We work with a RadGridView with 145000 rows and 4 columns. We use copy-paste to move data around from other apps and the application with build with Telerik.
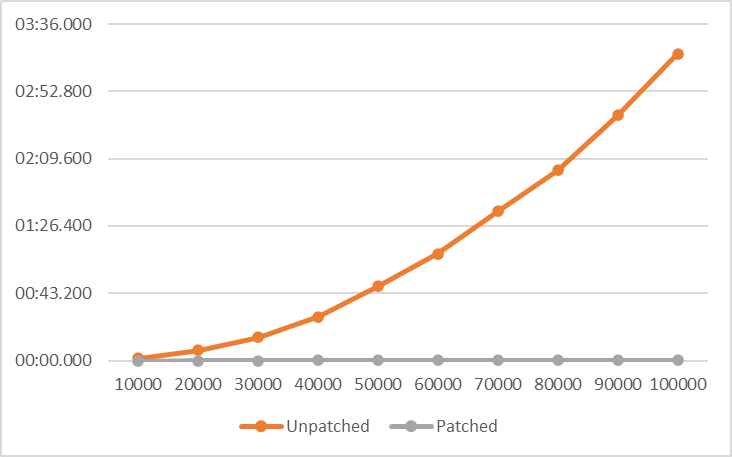
When we copy a flat file (with tabs delimited fields) and we paste it to the RadGridView, the whole process is painfully slow. The function to retrieve the data from the clipboard takes minutes (maybe hours, I cancelled it). It tracked the cause down to the StringTokenizer class. The tokenizer splits the string up into separate fields. But after extracting a field it creates a new copy of that string (containing about 10MB of data) minus the field. I patched it (with HarmonyX) and now it takes only one second:
static class StringTokenizerPerformancePatch
{
static private readonly InstanceFieldAccessor<StringTokenizer, LinkedList<string>> _tokens = new InstanceFieldAccessor< StringTokenizer, LinkedList<string>>("tokens");
static private readonly InstanceFieldAccessor<StringTokenizer, string> _sourceString = new InstanceFieldAccessor<StringTokenizer, string>("sourceString");
static private readonly InstanceFieldAccessor< StringTokenizer, string> _delimiter = new InstanceFieldAccessor<StringTokenizer, string>("delimiter");
static private readonly InstanceFieldAccessor< StringTokenizer, IEnumerator<string>> _enumerator = new InstanceFieldAccessor<StringTokenizer, IEnumerator<string>>("enumerator");
[HarmonyPatch(typeof(StringTokenizer), "Tokenize")]
staticclassPatch_StringTokenizer_Tokenize
{
static bool Prefix(StringTokenizer __instance)
{
var tokens = _tokens.GetValue(__instance);
var sourceString = _sourceString.GetValue(__instance);
var delimiter = _delimiter.GetValue(__instance);
Tokenize(tokens, sourceString, delimiter);
_enumerator.SetValue(__instance, tokens.GetEnumerator());
returnfalse;
}
static private void Tokenize(LinkedList<string> tokens, string text, string delimiter)
{
tokens.Clear();
if (string.IsNullOrEmpty(text))
return;
int index = 0;
while(true)
{
var index2 = text.IndexOf(delimiter, index, StringComparison.Ordinal);
if (index2 < 0)
{
tokens.AddLast(text.Substring(index));
break;
}
string token = text.Substring(index, index2 - index);
tokens.AddLast(token);
index = index2 + delimiter.Length;
}
}
}
}
- If delimiters are one character, why not use String.Split?
- Why use a LinkedList?