Recently Updated
Unplanned
Last Updated:
27 Jul 2023 05:53
by Helen
Created by:
Helen
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Find is skipping the first match in a specific document.
Completed
Last Updated:
10 Jul 2023 09:57
by ADMIN
Release R2 2023 SP1
Created by:
James
Comments:
0
Category:
PDFViewer
Type:
Bug Report
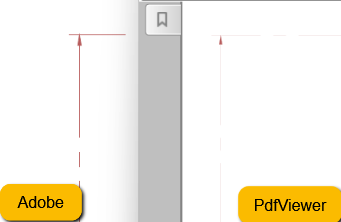
The thinnest line thickness is thinner than in Adobe and it is not scaled according to the scale factor.
Observed:
Unplanned
Last Updated:
10 Jul 2023 08:28
by Mattia
Created by:
Mattia
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Form XObject with Matrix property is displayed with misplaced position when imported with PdfProcessing
Completed
Last Updated:
05 Jul 2023 10:51
by ADMIN
Release R2 2023 SP1
Created by:
Sebastien
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Path geometries with a small thickness value are not displayed correctly
Completed
Last Updated:
05 Jul 2023 08:11
by ADMIN
Release R2 2023 SP1
Created by:
Georgi
Comments:
0
Category:
PDFViewer
Type:
Bug Report
When importing a document with empty pages collection an ArgumentNullException: 'Value cannot be null.
Parameter name: page', is thrown, which leads to application crash.
Workaround: Import the document using the PdfProcessing library and add an empty page:
PdfFormatProvider pdfProcessingFormatProvider = new PdfFormatProvider();RadFixedDocument document = pdfProcessingFormatProvider.Import(stream); if (document.Pages.Count == 0){ document.Pages.AddPage();}
Completed
Last Updated:
04 Jul 2023 10:46
by ADMIN
Release R3 2023 SP1
Created by:
Michael
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Unsupported annotations are rendered on top of other content. When there is a form field that appears inside the annotation, it cannot be clicked or interacted with as the annotation is capturing the mouse gestures.
Completed
Last Updated:
28 Jun 2023 15:20
by ADMIN
Release R2 2023 SP1
ADMIN
Created by:
Tanya
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Document cannot be loaded because the Encrypt property is not set and is null.
Completed
Last Updated:
28 Jun 2023 14:56
by ADMIN
Release R2 2023 SP1
ADMIN
Created by:
Tanya
Comments:
0
Category:
PDFViewer
Type:
Bug Report
The UserDict collection is not parsed and the procedures for the operators are unavailable. The exception is thrown while trying to read the font file of the Univers and Univers Bold fonts. Internally, an ArgumenNullException is thrown, which results in missing content when the document is shown in RadPdfViewer.
Completed
Last Updated:
27 Jun 2023 14:51
by ADMIN
Release R2 2023 SP1
Created by:
Mingchang
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Some Chinese characters cannot be found in s a specific Cmap.
Completed
Last Updated:
27 Jun 2023 14:49
by ADMIN
Release R2 2023 SP1
Created by:
Guy
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Documents containing large images are slow to decompress and decode.
Completed
Last Updated:
27 Jun 2023 13:52
by ADMIN
Release R2 2023 SP1
ADMIN
Created by:
Deyan
Comments:
1
Category:
PDFViewer
Type:
Bug Report
All annotations are missing because ArgumentNullException is thrown while importing page annotations. The exception is handled and all non-annotation related pdf content is loaded successfully.
Completed
Last Updated:
27 Jun 2023 11:55
by ADMIN
Release R2 2023 SP1
Created by:
Georgi
Comments:
1
Category:
PDFViewer
Type:
Bug Report
When saving Form Fields in document defined with linearized PDF structure, it produces a document that fails to open in Edge.
The current implementation of the RadPdfViewer Save uses the incremental update feature. However, the incremental update doesn't comply with the linearized structure and the document fails to open in some viewers.
Workaround: Import/export the document with PdfPRocessing to remove the linearization feature.
The current implementation of the RadPdfViewer Save uses the incremental update feature. However, the incremental update doesn't comply with the linearized structure and the document fails to open in some viewers.
Workaround: Import/export the document with PdfPRocessing to remove the linearization feature.
Completed
Last Updated:
27 Jun 2023 10:20
by ADMIN
Release R2 2023 SP1
ADMIN
Created by:
Georgi
Comments:
3
Category:
PDFViewer
Type:
Bug Report
When importing document containing a destination which points to invalid page reference, KeyNotFoundException is thrown.
Completed
Last Updated:
27 Jun 2023 08:46
by ADMIN
Release R2 2023 SP1
Created by:
Andre
Comments:
1
Category:
PDFViewer
Type:
Bug Report
By specification, when some of the destination parameters have null value, the current value of that parameter is to be retained unchanged (This rule applies for most of the properties). For example, if Location (XYZ) destination is imported and any of the left, top, or zoom parameters is null, the current value of the visual viewport for the specified property should be retained.
Workaround: Edit the document destinations and set default values. For example if the document contains Location destinations the Left, Top and Zoom properties can be set:
foreach (var annotation in document.Annotations)
{
Link link = annotation as Link;
if (annotation != null)
{
if (link.Destination is Location location)
{
location.Left = location.Left != null ? location.Left : 0;
location.Top = location.Top != null ? location.Top : 0;
location.Zoom = location.Zoom != null ? location.Zoom : 1;
}
}
}
Workaround: Edit the document destinations and set default values. For example if the document contains Location destinations the Left, Top and Zoom properties can be set:
foreach (var annotation in document.Annotations)
{
Link link = annotation as Link;
if (annotation != null)
{
if (link.Destination is Location location)
{
location.Left = location.Left != null ? location.Left : 0;
location.Top = location.Top != null ? location.Top : 0;
location.Zoom = location.Zoom != null ? location.Zoom : 1;
}
}
}
Completed
Last Updated:
26 Jun 2023 14:25
by ADMIN
Release R2 2023 SP1
Created by:
Paul
Comments:
1
Category:
PDFViewer
Type:
Bug Report
Text characters are missing when document is loaded in RadPdfViewer. When Fit to Page is used then numerous text characters vanish. They do not reappear when zooming back in.
Completed
Last Updated:
26 Jun 2023 14:08
by ADMIN
Release R2 2023 SP1
Created by:
Sanjeev
Comments:
3
Category:
PDFViewer
Type:
Bug Report
The offset of the Page boundaries such as CropBox, MediaBox, BleedBox, and ArtBox is not respected and is always treated as 0 which causes misplaced Annotations.
Completed
Last Updated:
26 Jun 2023 14:03
by ADMIN
Release R2 2023 SP1
ADMIN
Created by:
Anna
Comments:
1
Category:
PDFViewer
Type:
Bug Report
When a page is rotated its annotations are not positioned correctly.
Completed
Last Updated:
26 Jun 2023 13:56
by ADMIN
Release R2 2023 SP1
ADMIN
Created by:
Anna
Comments:
1
Category:
PDFViewer
Type:
Bug Report
When the file has an annotation with a destination and this destination is missing from the destinations (Dests) collection of the catalogue, KeyNotFoundException is thrown when you try to scroll to the page where the annotation is located. A better behavior would be for nothing to happen when trying to click on the annotation leading to the destination.
Completed
Last Updated:
26 Jun 2023 13:51
by ADMIN
Release R2 2023 SP1
ADMIN
Created by:
Kammen
Comments:
3
Category:
PDFViewer
Type:
Bug Report
When a PDF document contains images compressed with CCITTFaxDecode with applied BlackIs1 parameter, black color is visualized as white and white as black.
Completed
Last Updated:
26 Jun 2023 13:21
by ADMIN
Release R2 2023 SP1
ADMIN
Created by:
Deyan
Comments:
1
Category:
PDFViewer
Type:
Bug Report
Default DctDecode implementation uses System.Windows.Media.Imaging.BitmapImage in order to get the image pixels. However, when the image uses some complex colorspace (for instance Separation based on CMYK) the BitmapImage is initialized with a different format and we use System.Windows.Media.Imaging.FormatConvertedBitmap in order to get the pixels in CMYK colorspace. There seems to be some issue with these calculations as the resulting image has incorrect pixels.
WORKAROUND: You may inherit DctDecode class in order to implement custom decoder and call DecodeWithJpegDecoder method from the base class as mentioned in the note of this documentation article:
http://docs.telerik.com/devtools/wpf/controls/radpdfviewer/customization-and-extensibility/customize-pdf-rendering
A sample implementation of these custom decoder may be seen below:
public class CustomDctDecode : DctDecode
{
public override byte[] Decode(PdfObject decodedObject, byte[] inputData, DecodeParameters parms)
{
return DecodeWithJpegDecoder(inputData);
}
}