Some characters (for example, German Umlauts "Ü") render incorrectly when using a specific DPI setting and zoom level in the Standalone Report Designer during design/preview.
I've found out this is due to the dots on the U are out of the text rect when the vertical align is set to top (which is the default). It appears they get cut off because they exceed the boundaries of the text box.
I am using the HTML5-based Blazor report viewer, with the parameters area position set to "top":
<ReportViewer @ref="reportViewer1"
ViewerId="rv1"
ServiceUrl="/api/reports"
ReportSource="@(new ReportSourceOptions
{
Report = "SampleReport.trdp",
})"
Parameters="@(new ParametersOptions { Editors =
new EditorsOptions { MultiSelect = EditorType.ComboBox, SingleSelect = EditorType.ComboBox }
})"
ScaleMode="@(ScaleMode.Specific)"
Scale="1.0"
ParametersAreaPosition="@(ParametersAreaPosition.Top)"
EnableAccessibility="false"/> However, this causes the content of the parameters area to align incorrectly:
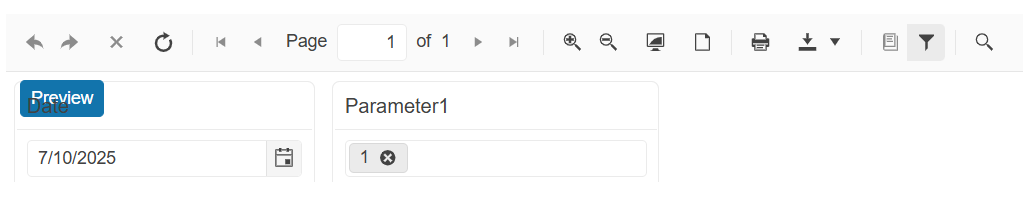
I have multiline text in a TextBox item that has its Style > TextAlign set to Center.
It is rendered as expected with the GDI+ graphics engine.
When I switch to the Skia graphics engine in the Standalone Designer .NET, though, some lines are not centered correctly in PDF rendering:

In Preview of the designer, with PNG and OpenXML export the text is shown as expected.
When exporting an SVG image to PDF, polylines with stroke-dasharray are rendered incorrectly — the dash pattern is not applied.
Additionally, polylines with a stroke-width exhibit visual artifacts such as pixelation or inconsistent thickness.
Step by step instructions or code snippets how to reproduce the problem
- Save svg content (see below) as a file c:\test_svg_line_stroke.svg
- Create an empty report
- Add a picture box
- Select a value for the picture box - use file c:\test_svg_line_stroke.svg
- Go to preview - SVG is correct
- Click Export->Acrobat (PDF) file and export a PDF file
- Open PDF file to verify that the red line in a bottob does not have stroke-dasharray applied
If there's no black line with no stroke-dasharray - the red line in a bottom looks correct
test_svg_line_stroke.svg
<svg version="1.1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xml="http://www.w3.org/XML/1998/namespace" width="500" height="400" viewBox="0, 0, 500, 400" preserveAspectRatio="xMinYMin" transform="scale(1)">
<polyline points="100, 100 400, 100" stroke-width="7" stroke-dasharray="40 40" style="fill:none;stroke:#FF0000;" />
<polyline points="100, 200 400, 200" stroke-width="5" style="fill:none;stroke:#000000;" />
<polyline points="100, 300 400, 300" stroke-width="7" stroke-dasharray="40 40" style="fill:none;stroke:#FF0000;" />
</svg>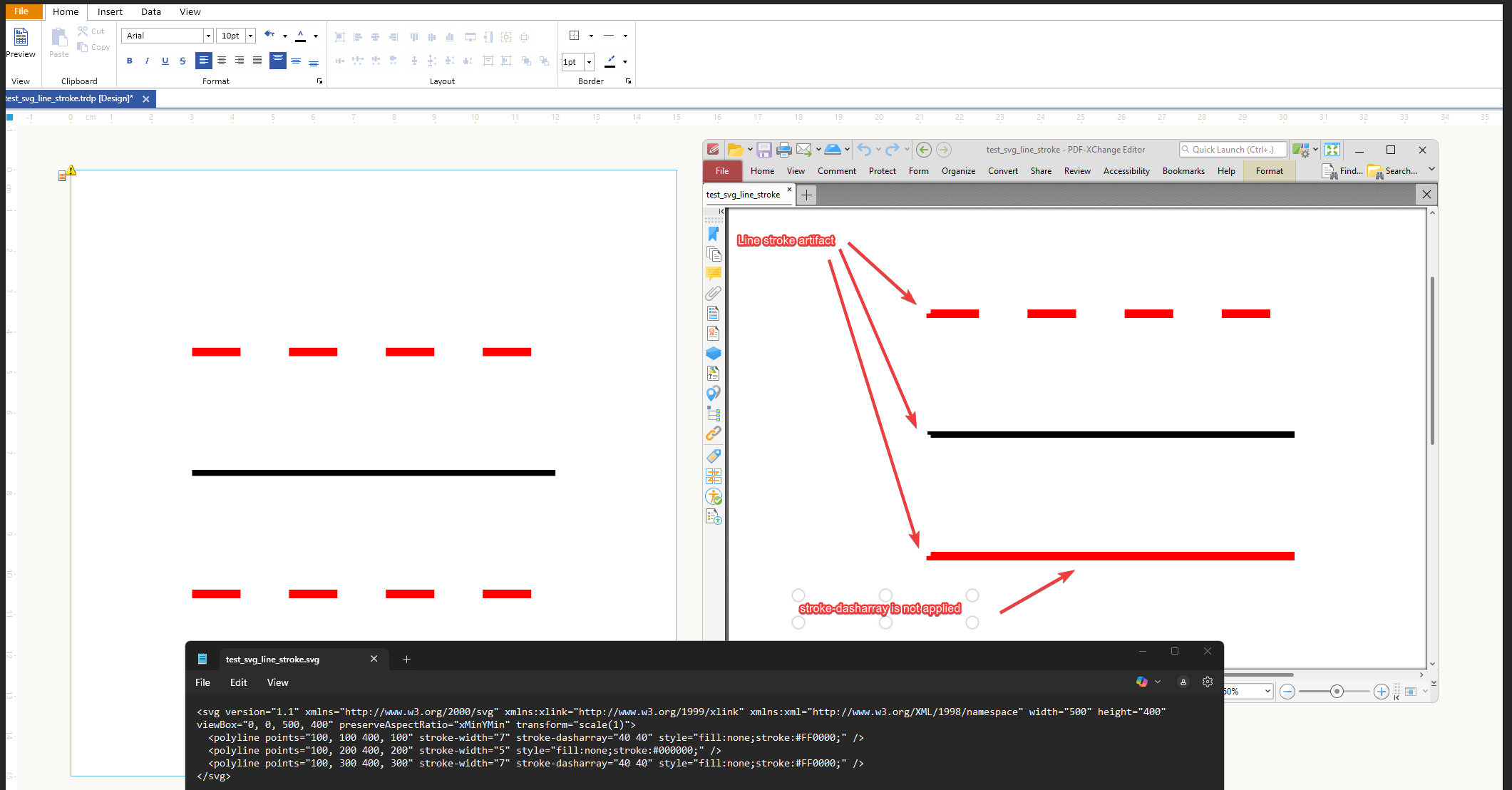
test_svg_line_stroke.svg - svg source file
test_svg_line_stroke.trdp - report with a picture box with SVG image
test_svg_line_stroke.pdf - generated PDF file
When the WinForms Report Viewer is initialized from within the Form.Load Event, and the RefreshReport() method of the viewer is invoked before it is added to a parent form, the following exception will be thrown:
Telerik.ReportViewer.WinForms.Licensing.UiLicensePresenter.ShowWatermark(Action showWatermarkCallback) at Telerik.ReportViewer.Common.TelerikLicensePresenterBase.PresentWatermark(Action showWatermarkCallback) at Telerik.ReportViewer.WinForms.WinViewer.OnPaint(PaintEventArgs eventArgs) at System.Windows.Forms.Control.PaintWithErrorHandling(PaintEventArgs e, Int16 layer) at System.Windows.Forms.Control.WmPaint(Message& m) at System.Windows.Forms.Control.WndProc(Message& m) at System.Windows.Forms.Control.ControlNativeWindow.WndProc(Message& m) at System.Windows.Forms.NativeWindow.Callback(HWND hWnd, MessageId msg, WPARAM wparam, LPARAM lpa
I run an ASP.NET Core application that has the functionality to export reports into PDFs in an Azure environment.
There is no way to install additional fonts on Azure so I provide the fonts used in my reports via the "privateFonts" element of the Reporting configuration.
This works for the most part, the font is embedded in the produced PDFs but if I have a textbox with a large text, the text may be cut off when using the Skia engine.
I tested running my application in Docker, I copied the needed fonts in the usr/share/fonts directory of the Docker Linux container, and tried exporting again.
When exporting from Docker, with the fonts installed in the container, the text is not cut off. It seems that there is an issue when the fonts are provided as private fonts.
Hello SupportTeam,
when using privateFonts, the WPF-ReportViewer does not use the correct-FontFile when multiple Font-Files are present in the same folder.
The used Graphics-Engine is GDI.
Example 1:
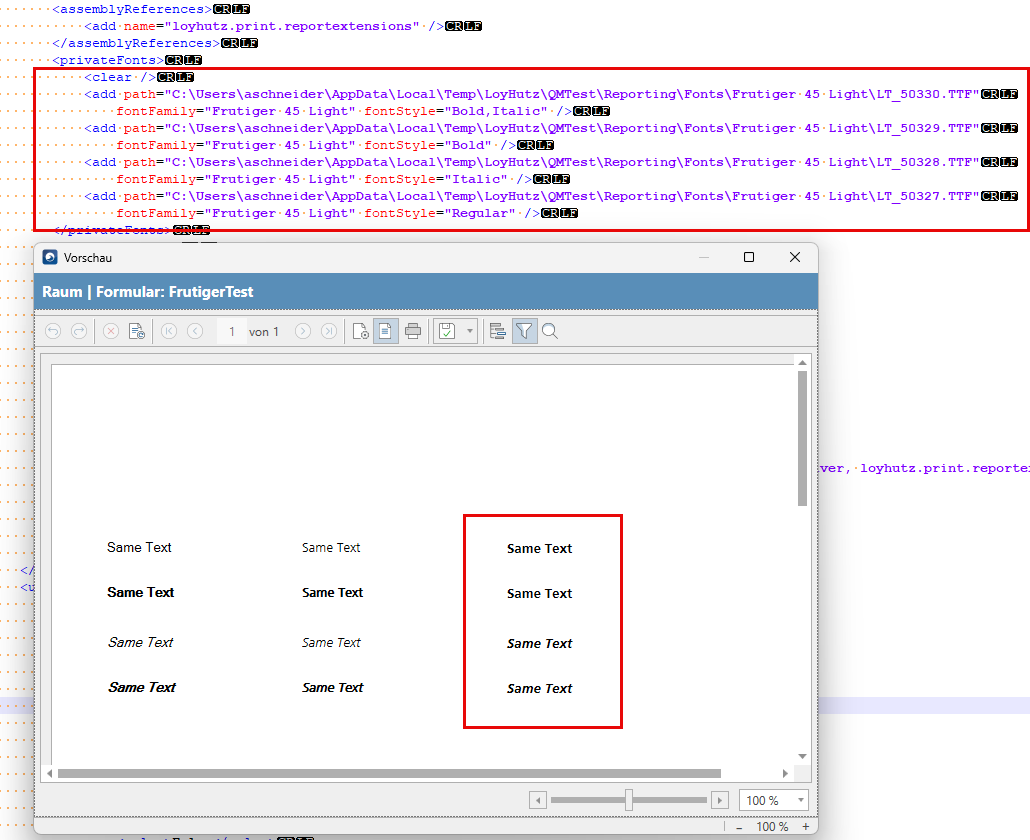
When putting every File in its own Folder it works as expected.
Example 2:
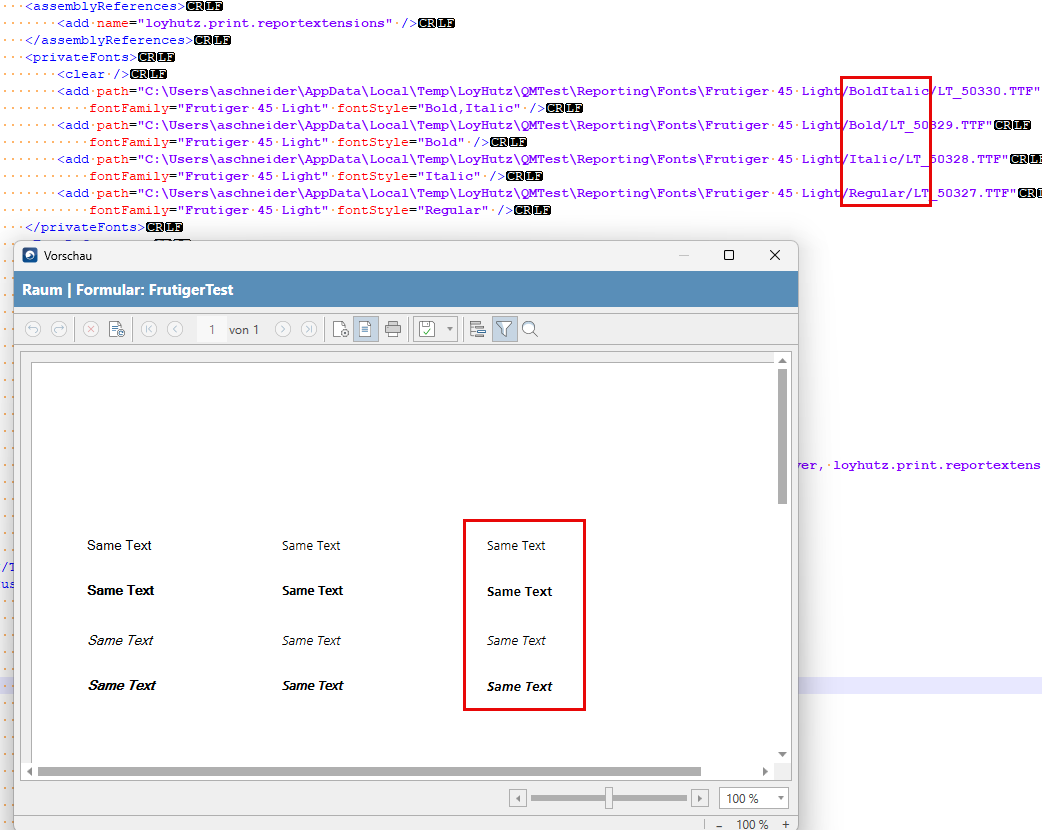
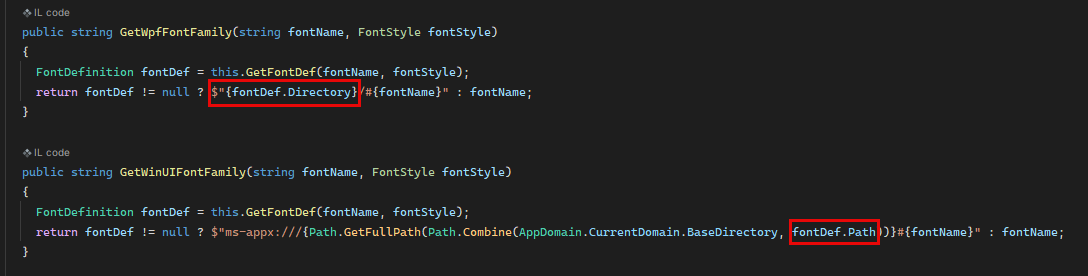
During debugging, we noticed that in case of WPF, the Directory is passed instead of the Full file Path:
In class: Telerik.Reporting.Processing.Common.FontContainer
Best regards
Alexander Schneider
I have a main report - "MainReport.trdp" and a report that I use in the detail section of the main report as a subreport twice - "SubReport.trdp".
In "SubReport.trdp", I have a report parameter whose value I use in one of the calculated fields in its data source component.
The calculated field's expression is evaluated based on the report parameter value passed with the SubReport's ReportSource object of the first SubReport item for both subreports.
For example, if I pass the string "A" to the first subreport's parameter and the string "B" to the second, the calculated field in both instances will evaluate based on the first value, in this case - "A".
The second subreport should evaluate the calculated field based on the value passed to its report parameter, it should not matter if I have the same report rendered as a subreport multiple times and whether a different parameter value is passed to them.
In version 19.1.25.521, I am updating the report source of the viewer immediately after calling $("#reportViewer1").telerik_ReportViewer. This now results in an error:
TypeError: undefined is not iterable (cannot read property Symbol(Symbol.iterator))
In previous versions, it used to work.
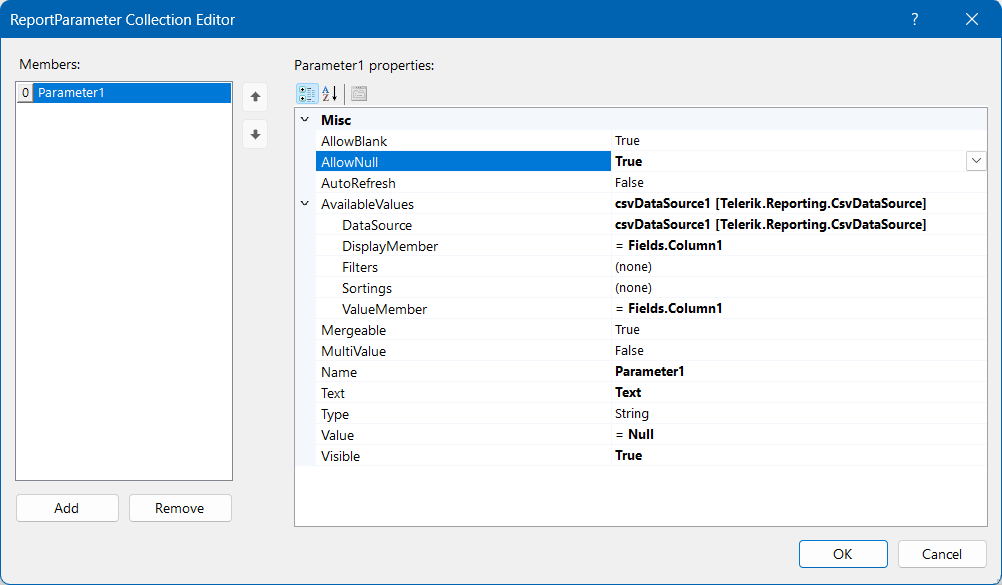
I have created a report parameter that accepts null as a value(AllowNull=True) and have set null as the default value by using the expression =Null on the Value property of the report parameter.
This report parameter also has a data source assigned to it so it has available values. Here is a look at the full setup:
When I call the "getReportParameters()" function on the HTML5 Report Viewer, there is an exception thrown in the console that looks as follows:
telerikReportViewer:1 Error: The available values of parameter Parameter1 do not contain Value property that equals null
at Ae (telerikReportViewer:1:45529)
at Object.getReportParameters (telerikReportViewer:1:38265)
at Object.getReportParameters (telerikReportViewer:1:108469)
at <anonymous>:1:50
The above image is from testing in HTML5Interactive rendering with Skia on Windows.
Hi
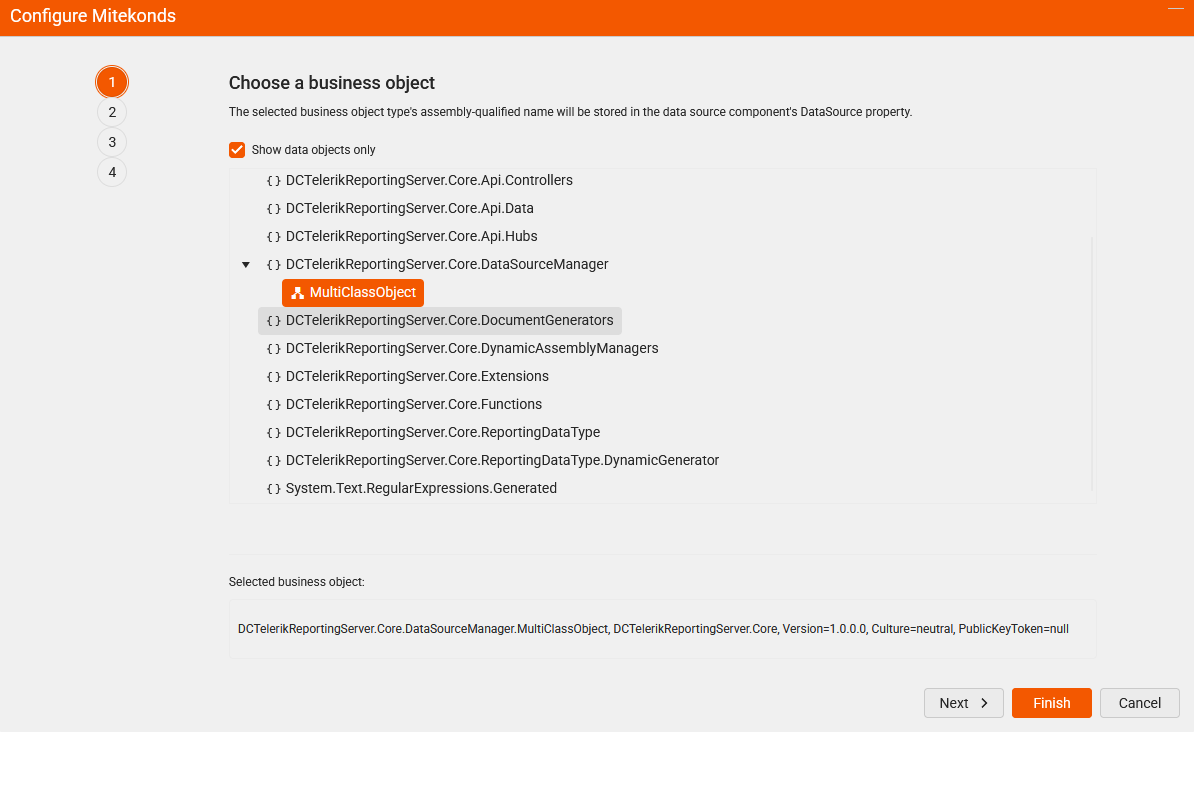
Currently, when referencing an assembly from appsettings.json in telerikReporting:assemblyReferences , the Object Data Source wizard in Telerik Web Reporting displays all namespaces from that assembly, even if only one class is marked with [DataObject]. This results in unnecessary namespace clutter and can confuse report designers, especially in large projects where only a single data object is intended for reporting. See screenshots below:

Please provide a way to control which namespaces and/or classes are visible in the Object Data Source wizard. Possible solutions could include:
• Only displaying namespaces that contain [DataObject] classes (filtering namspaces with no elments to display)
• Allowing explicit inclusion/exclusion of namespaces or classes via configuration (e.g., in appsettings.json).
• Supporting an attribute (such as [Browsable(false)] or a new custom attribute) to hide specific classes or namespaces from the wizard UI.
Thank you for considering this improvement!
I am rendering reports locally using the report processor. When I use the RenderReport method after processing MS Office Documents and PDF files with the Spire. Office, it causes the text of the report rendered with Telerik Reporting to get truncated:
using Telerik.Reporting;
Spire.Doc.Document document = new Spire.Doc.Document();
var wordDocPath = "./wordtest.docx";
var pdfFilePath = System.IO.Path.Combine("../../../", "wordtest.pdf");
document.LoadFromFile(wordDocPath);
Spire.Doc.ToPdfParameterList toPdf = new Spire.Doc.ToPdfParameterList();
//toPdf.AutoFitTableLayout = true;
document.SaveToFile(pdfFilePath, toPdf);
document.Close();
var reportProcessor = new Telerik.Reporting.Processing.ReportProcessor();
var reportPackager = new ReportPackager();
string sourceReportFile = "./Static Broken CSU Analysis.trdp"; ;
using (var sourceStream = System.IO.File.OpenRead(sourceReportFile))
{
var report = (Report)reportPackager.UnpackageDocument(sourceStream);
var deviceInfo = new System.Collections.Hashtable();
var reportSource = new InstanceReportSource();
reportSource.ReportDocument = report;
Telerik.Reporting.Processing.RenderingResult result = reportProcessor.RenderReport("PDF", reportSource, deviceInfo);
if (!result.HasErrors)
{
string fileName = result.DocumentName + "." + result.Extension;
string filePath = System.IO.Path.Combine("../../../", fileName);
using (System.IO.FileStream fs = new System.IO.FileStream(filePath, System.IO.FileMode.Create))
{
fs.Write(result.DocumentBytes, 0, result.DocumentBytes.Length);
}
}
}If I comment out the section that is converting the totally unrelated word file to pdf and run it again, it does not clip.
As soon as I set an AccessibleDescription on a cell (especially the first cell in a row), NVDA stops reading the rest of the row. It seems like the table reading order is broken, and the screen reader exits the table structure or skips over the remaining cells to go to the next row.
This is obviously a problem for users relying on screen readers, and I’m not sure how to fix it. Has anyone else dealt with this in Telerik Reporting, or know a workaround to make screen readers read both the custom alt text and maintain proper row navigation?
I’m working on a project that requires generating Section 508-compliant PDFs, and I’m using Telerik Reporting to build the accessible reports. However, I’ve run into a problem with how screen readers—specifically NVDA—are interpreting table content.
In my report’s table, some values like 12/01/2023 aren’t being read as dates, and values like (192,340.00)—which represent negative numbers—aren’t being interpreted as “negative” or addressing the parenthesis.
With the 2025 Q2 release, the 3-parameter AddTelerikReporting static method was replaced with a 4-parameter method containing an additional argument for the optional AIClientFactory method of the REST Service.
The original method should be returned to avoid breaking projects that do not implement an AIClientFactory.