Recently Updated
Unplanned
Last Updated:
19 Apr 2022 12:45
by Dimitar
Created by:
Dimitar
Comments:
0
Category:
PDFViewer
Type:
Feature Request
Implement editor functionalities like add, edit or delete content.
Unplanned
Last Updated:
08 Apr 2022 13:24
by Joe
Created by:
Joe
Comments:
0
Category:
PDFViewer
Type:
Feature Request
When rendering PDF file with a TrueType font and Unicode platform Id (platformId: 0), glyphs are not obtained from CMAP table and are displayed with default rectangle placeholders.
Completed
Last Updated:
08 Apr 2022 07:29
by ADMIN
Release LIB 2022.1.411 (11 Apr 2022)
Created by:
Bjarke
Comments:
0
Category:
PDFViewer
Type:
Bug Report
The leak is reproducible when printing documents without UI and results in multiple instances of DocumentPrintPresenter kept alive in the memory.
Unplanned
Last Updated:
23 Mar 2022 09:31
by Uma
Created by:
Uma
Comments:
0
Category:
PDFViewer
Type:
Feature Request
This type of dictionary allows users to specify files and define different files for different systems or platforms.
Unplanned
Last Updated:
23 Mar 2022 07:23
by Joseph
Created by:
Joseph
Comments:
0
Category:
PDFViewer
Type:
Bug Report
The image quality is poor when rendering large images.
Unplanned
Last Updated:
22 Feb 2022 11:44
by Vojtech
Created by:
Vojtech
Comments:
0
Category:
PDFViewer
Type:
Bug Report
PDFViewer crashes, when used on a tablet, Text selection is activated and text is selected in Touch mode.
Unplanned
Last Updated:
10 Feb 2022 11:03
by ADMIN
Created by:
Yassir
Comments:
2
Category:
PDFViewer
Type:
Feature Request
Allow passing specific pages (e.g. "1, 4, 6") and more than one page range (e.g. "1-3, 6-7") to the print dialog`s Pages page range.
Completed
Last Updated:
07 Feb 2022 14:06
by ADMIN
Release R1 2022 SP1
Created by:
Jose Ramon
Comments:
0
Category:
PDFViewer
Type:
Bug Report
A rectangle is rendered as a solid rectangle instead of a rectangle with no fill.
Completed
Last Updated:
20 Jan 2022 08:17
by ADMIN
Release R1 2022
ADMIN
Created by:
Kammen
Comments:
2
Category:
PDFViewer
Type:
Feature Request
Dialog for inputting the password should be implemented in order to be able to decrypt the file content.
Unplanned
Last Updated:
05 Jan 2022 11:06
by ADMIN
Created by:
note prj
Comments:
0
Category:
PDFViewer
Type:
Feature Request
Currently, a NotSupportedException is thrown and handled internally. As a result, the image is missing from the page content.
Unplanned
Last Updated:
04 Jan 2022 09:37
by ADMIN
Created by:
Vincenzo
Comments:
0
Category:
PDFViewer
Type:
Bug Report
When the Textbox` text alignment is set to top (multiline) left when entering in edit mode the alignment is changing to center-left (check the attached record.gif).
Unplanned
Last Updated:
19 Nov 2021 09:00
by ADMIN
ADMIN
Created by:
Martin
Comments:
0
Category:
PDFViewer
Type:
Bug Report
It is actually checked and only the appearance is wrong. When the file is saved the checkboxes states are as expected.
This behavior is observed with PdfImportSettings.ReadOnDemand setting only.
Unplanned
Last Updated:
10 Nov 2021 09:08
by Oliver
Created by:
Oliver
Comments:
1
Category:
PDFViewer
Type:
Bug Report
COMException: 'Exception from HRESULT: 0x8052000C' breaks the printing of the a specific document.
Unplanned
Last Updated:
27 Oct 2021 13:34
by ADMIN
Created by:
Andri
Comments:
0
Category:
PDFViewer
Type:
Bug Report
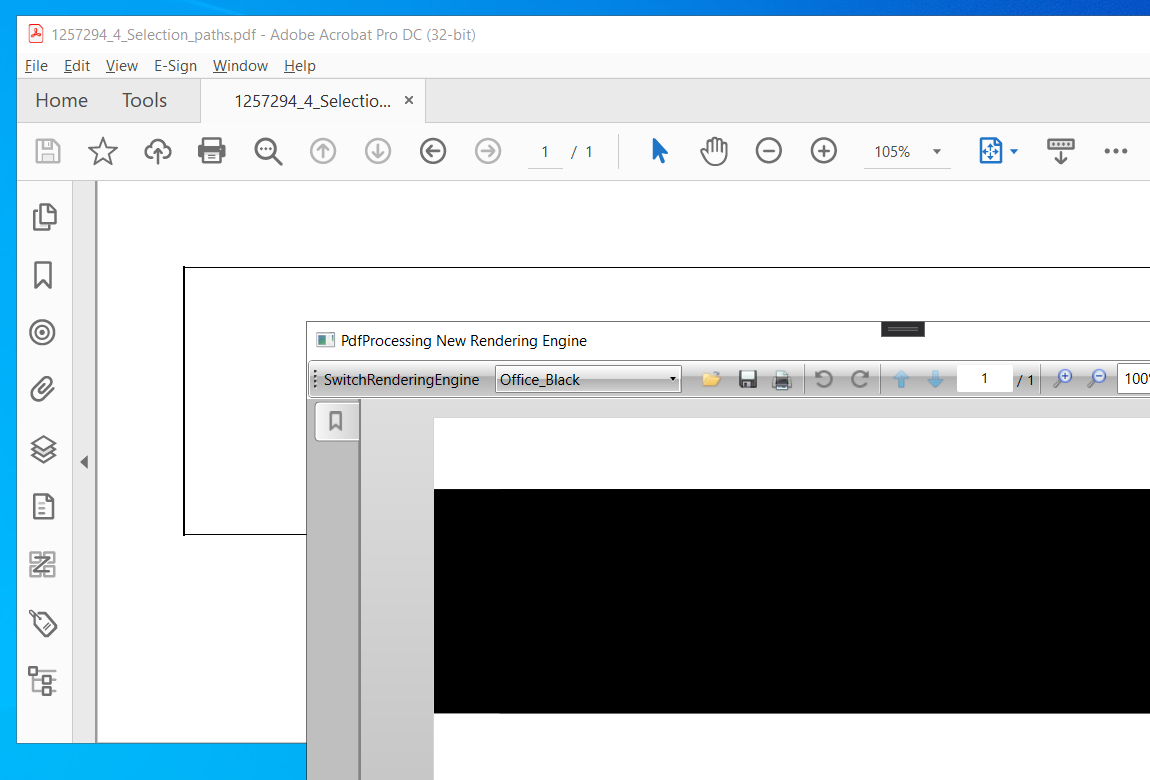
While all the pages and components of the control are rendered on the image, the content is completely missing from it. The issue is a regression caused by the migration of the model and its async rendering introduced in R3 2020.
Workaround: Fallback to the old rendering engine:
- Changing the default behavior:
this.pdfViewer.DefaultImportSettings.UseOldRendering = true;- Setting the property to the format provider used to show the document:
PdfImportSettings settings = PdfImportSettings.ReadOnDemand;
settings.UseOldRendering = true;
Unplanned
Last Updated:
26 Oct 2021 08:03
by ADMIN
Created by:
Olivier
Comments:
0
Category:
PDFViewer
Type:
Bug Report
When the color of the image is using the CMYK color model, DctDecode filter is applied, and there is no ColorTransform set the colors of the image are inverted.
Unplanned
Last Updated:
25 Oct 2021 12:45
by Sven
Created by:
Mi
Comments:
3
Category:
PDFViewer
Type:
Feature Request
When using CTRL+Mousewheel to zoom in to a PDFViewer document, it should zoom into the point where the mouse pointer is located. Currently it just does a simple zoom of the whole document. For example see Acrobat Reader or Google Maps.
Completed
Last Updated:
21 Oct 2021 13:54
by ADMIN
Release LIB 2021.3.1025 (25 Oct 2021)
Created by:
n/a
Comments:
0
Category:
PDFViewer
Type:
Bug Report
PDFViewer: InvalidOperationException (The calling thread cannot access this object because a different thread owns it) when scrolling a specific document.
Completed
Last Updated:
19 Oct 2021 13:47
by ADMIN
Release LIB 2021.3.1025 (25 Oct 2021)
Created by:
Shakti SIngh Dulawat
Comments:
0
Category:
PDFViewer
Type:
Bug Report
By specification, the InteractiveForm fields can have the same name if they are descendants of a common ancestor. Such fields are different representations of the same underlying field; they should differ only in properties that specify their visual appearance. When such a document is imported an ArgumentException: 'An item with the same key has already been added.' is thrown, which leads to non-editable fields in RadPdfViewer.
Completed
Last Updated:
20 Sep 2021 09:04
by ADMIN
Release LIB 2021.3.920 (20 Sep 2021)
Created by:
Dexter
Comments:
0
Category:
PDFViewer
Type:
Bug Report
When trying to digitally sign a document an exception is thrown: System.NullReferenceException: 'Object reference not set to an instance of an object.'
Completed
Last Updated:
20 Sep 2021 08:59
by ADMIN
Release LIB 2021.3.920 (20 Sep 2021)
Created by:
Martin
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Wrong calculation of glyphs widths.