SEARCH function with the following format is valid only in Excel 365/2021 or later (with dynamic array support).
"=SEARCH({"Alpha","Beta","Gamma","Delta","Omega","Sigma","Zeta"}, "Omega")"
• It returns an array of numbers or errors, showing the position of each substring in "Omega".
• If a substring is found, you get its position (e.g., 1 for "Omega"); if not, you get #VALUE!.
In Excel formulas, the double minus (--) is known as the "double unary operator." Its main purpose is to convert Boolean values (TRUE/FALSE) into numeric values (1/0).
How it works:
• TRUE becomes 1
• FALSE becomes 0
Example: Suppose you have an array formula like:
=SUM(--(B2:B20="Gamma"))
• (B2:B20="Gamma") produces an array of TRUE/FALSE.
• --(B2:B20="Gamma") converts that array to 1/0.
• SUM(...) then adds up the number of matches.
Some Excel functions (like SUM, SUMPRODUCT) require numbers, not Booleans.
The double unary is a concise way to force this conversion.
This causes issues when calculating element positions in a custom WorksheetUILayerBase in the context of RadSpreadsheet for WPF.
Currently, if you have a decimal column in the DataTable, it is imported as a text column in the workbook. It should be preserved as a numeric column after importing.
Note: When importing a DataTable, each of the column's type is checked and a respective cell type is imported.
if (dataType.IsValueType && dataType.IsPrimitive && !dataType.IsEnum)
{
newValue = new NumberCellValue(Convert.ToDouble(value));
}The check ensures only “simple” CLR value types are treated as numbers when importing from DataTable to the worksheet.• IsValueType: filters out reference types.
• IsPrimitive: narrows to CLR primitives (sbyte, byte, short, ushort, int, uint, long, ulong, float, double, char, IntPtr, UIntPtr, bool).
• !IsEnum: excludes enums.
In this code path, primitives are interpreted as numeric and converted to a Double for NumberCellValue. This avoids trying to numeric-convert arbitrary structs (e.g., guid, TimeSpan, custom structs), which should not be treated as numbers.
Decimal is not primitive, so it falls back to text, losing numeric semantics. This is the reason for the observed behavior.
Currently, RadSpreadProcessing supports the following options:
namespace Telerik.Windows.Documents.Model.Drawing.Charts
{
/// <summary>
/// Specifies where a chart legend is placed relative to the plot area.
/// </summary>
public enum LegendPosition
{
/// <summary>
/// Positions the legend to the right of the plot area.
/// </summary>
Right,
/// <summary>
/// Positions the legend below the plot area.
/// </summary>
Bottom,
/// <summary>
/// Positions the legend to the left of the plot area.
/// </summary>
Left,
/// <summary>
/// Positions the legend above the plot area.
/// </summary>
Top
}
}MS Excel supports setting "Top Right" Legend Position:
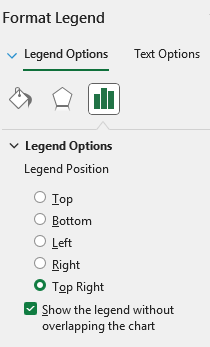
An error occurs while importing an XLSX document with charts. Here is the stack trace:
at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Contexts.XlsxWorkbookImportContext.PairSeriesGroupsWithAxes() at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.Chart.PlotAreaElement.CopyPropertiesTo(IOpenXmlImportContext context, DocumentChart chart) at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.Chart.ChartElement.CopyPropertiesTo(IOpenXmlImportContext context, DocumentChart chart) at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.Chart.ChartSpaceElement.OnAfterRead(IOpenXmlImportContext context) at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.OpenXmlElementBase.Read(IOpenXmlReader reader, IOpenXmlImportContext context) at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Parts.ChartPart.Import(IOpenXmlReader reader, IOpenXmlImportContext context) at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Parts.OpenXmlPartBase.Import(Stream stream, IOpenXmlImportContext context) at Telerik.Windows.Documents.FormatProviders.OpenXml.OpenXmlImporter`1.ImportPartFromArchive(ZipArchiveEntry zipEntry, PartBase part, IOpenXmlImportContext context) at Telerik.Windows.Documents.FormatProviders.OpenXml.OpenXmlImporter`1.Import(Stream input, IOpenXmlImportContext context) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.XlsxFormatProvider.ImportOverride(Stream input, CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.WorkbookFormatProviderBase.Import(Stream input, Nullable`1 timeout)
RadSpreadProcessing expects an integer, instead of boolean. However, according to the specification, it should be boolean:
XlsFormatProvider: InvalidOperationException is thrown when importing a document with an unsupported BIFF record.
Workaround: Re-save the file with Excel before importing it.
The current formula:
<c r="A1" s="1">
<f>[1]BILANS_JI!$C$2</f>
<v>22611518.026189998</v>
</c>
• Simple direct reference to a single external cell [1]BILANS_JI!$C$2
• No function, just a linked cell
The expected value to be returned is 22611518.
at Telerik.Windows.Documents.Spreadsheet.Utilities.SpreadsheetHelper.UpdateFloatingImageSize(FloatingShapeBase shape) at Telerik.Windows.Documents.Spreadsheet.Utilities.SpreadsheetHelper.CalculateRotatableShapeBoundingRect(Point position, FloatingTransformableShape shape) at Telerik.Windows.Documents.Spreadsheet.Layout.RadWorksheetLayout.CalculateShapeBoundingRect(FloatingShapeBase shape) at Telerik.Windows.Documents.Spreadsheet.Layout.RadWorksheetLayout.UpdateShapesSizeAndPosition() at Telerik.Windows.Documents.Spreadsheet.Layout.RadWorksheetLayout.Measure(CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.Layout.RadWorksheetLayout.Measure(CellIndex frozenCellIndex, CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.Model.Workbook.UpdateWorksheetLayout(RadWorksheetLayout worksheetLayout, Worksheet worksheet, Boolean isForPrinting, CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.Model.Workbook.GetWorksheetLayout(Worksheet worksheet, Boolean isForPrinting, CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.Model.Workbook.GetWorksheetLayout(Worksheet worksheet, Boolean isForPrinting) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Contexts.XlsxWorksheetImportContext.ImportShapesSizes() at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Contexts.XlsxWorksheetImportContext.EndImport(XlsxWorkbookImportContext workbookContext) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Contexts.XlsxWorkbookImportContext.EndImport() at Telerik.Windows.Documents.FormatProviders.OpenXml.OpenXmlImporter`1.Import(Stream input, IOpenXmlImportContext context) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.XlsxFormatProvider.ImportOverride(Stream input, CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.WorkbookFormatProviderBase.Import(Stream input, Nullable`1 timeout)
Workbook wb = new Workbook();
Worksheet worksheet = wb.Worksheets.Add();
PatternFill fill = new PatternFill(PatternType.DiagonalStripe, Colors.Red, Colors.Transparent);
worksheet.Cells[0, 0].SetFill(fill);
string outputFilePath = "Sample.pdf";
File.Delete(outputFilePath);
Telerik.Windows.Documents.Spreadsheet.FormatProviders.Pdf.PdfFormatProvider pdfFormatProvider =
new Telerik.Windows.Documents.Spreadsheet.FormatProviders.Pdf.PdfFormatProvider();
//export to file
using (Stream output = File.OpenWrite(outputFilePath))
{
pdfFormatProvider.Export(wb, output, TimeSpan.FromSeconds(10));
}
Process.Start(new ProcessStartInfo() { FileName = outputFilePath, UseShellExecute = true });When I need to populate a cell that I find using a DefinedName I should parse RefersTo to get Worksheet name. But DefinedName class contains Scope property which has CurrentWorksheet and Workbook properties (internal). It would be very useful if these properties could be public.
A reference that refers to the same cell or range on multiple sheets. Example: =SUM(Den1:Den31!C10) will sum C10 from all sheets between Den1 and Den3.
When a formula contains new lines, it is parsed incorrectly as follows:
- When it is shared formula it breaks the imported expression and replaces it with #NAME? error.
- In normal case it simply preserves the formula string converting it to StringExpression.
Workaround: Remove the new lines in the formulas.
Have in mind that this code will fix the issue only for the second scenario, when the formula is not shared.
CellRange usedCellRange = workbook.ActiveWorksheet.UsedCellRange;
for (int row = usedCellRange.FromIndex.RowIndex; row < usedCellRange.ToIndex.RowIndex; row++)
{
for (int column = usedCellRange.FromIndex.ColumnIndex; column < usedCellRange.ToIndex.ColumnIndex; column++)
{
CellSelection cell = workbook.ActiveWorksheet.Cells[row, column];
ICellValue value = cell.GetValue().Value;
if (value.RawValue.Contains("\n"))
{
cell.SetValue(value.RawValue.Replace('\n', ' '));
}
}
}