Importing an XLSX workbook can crash with System.ArgumentNullException: Value cannot be null. Parameter name: key during Workbook.ResumeCalculationMapRegistration().
Root cause:• The XLSX import pipeline queued null RadExpression entries into pendingCalculationMapExpressions.
• CalculationMap.AddBatch() passed those entries into ExpressionDependencyMap.AddExpressionsBatch().
• GetOrCreateNodeWithCache() then called Dictionary.TryGetValue() with a null key, which threw the exception.
When opening an Xlsx file with conditional formatting I get an Exception:
"System.ArgumentNullException: 'Value cannot be null. (Parameter 'formatting')'
at Telerik.Windows.Documents.Spreadsheet.Model.ConditionalFormattings.ConditionalFormattingDxfRule..ctor(DifferentialFormatting formatting)
at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Model.Elements.Worksheets.ConditionalFormattingRuleElement.GetRule(DifferentialFormatting formatting)
at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Model.Elements.Worksheets.ConditionalFormattingRuleElement.OnAfterRead(IXlsxWorksheetImportContext context)
at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.OpenXmlElementBase.ReadChildElements(IOpenXmlReader reader, IOpenXmlImportContext context)
at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.OpenXmlElementBase.Read(IOpenXmlReader reader, IOpenXmlImportContext context)
at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.OpenXmlElementBase.ReadChildElements(IOpenXmlReader reader, IOpenXmlImportContext context)
at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.OpenXmlElementBase.Read(IOpenXmlReader reader, IOpenXmlImportContext context)
at Telerik.Windows.Documents.FormatProviders.OpenXml.OpenXmlImporter`1.ImportPartFromArchive(ZipArchiveEntry zipEntry, PartBase part, IOpenXmlImportContext context)
at Telerik.Windows.Documents.FormatProviders.OpenXml.OpenXmlImporter`1.Import(Stream input, IOpenXmlImportContext context)
at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.XlsxFormatProvider.ImportOverride(Stream input)
at WpfApp1.MainWindow.StartExcel() in C:\Users\larse\source\repos\WpfApp1\MainWindow.xaml.cs:line 49"
To quote my colleage: "After dissecting the Excel template file, I have isolated what is causing the issue. If conditional formatting is used to disable cell boarders it results in the error, if the conditional formatting is updated to turn the necessary borders white, instead of disabling the report exports correctly, the following screenshot also explains."
Reading a password protected archive by passing a wrong password doesn't notify the user that the password is wrong. Accessing one of the entries in the archive throws a generic "Invalid data" exception. Steps to reproduce: 1. Create a zip file with password. 2. Open the same archive with the API passing wrong password and then try to one of the entries. Observed: InvalidDataException is thrown when trying to read one of the entries in the archive. Expected: The exception should be more meaningful and if possible occur when reading the archive. There should be API allowing to check if the password is correct.
CellSelection.SetValue method causes memory leak of CellReferenceRangeExpression objects in some cases when cell value is referenced by formulas. The memory leak is small, but the remaining CellReferenceRangeExpression continue to listen to some events, causing performance issues when their number become large - the time to set the value increases with each set.
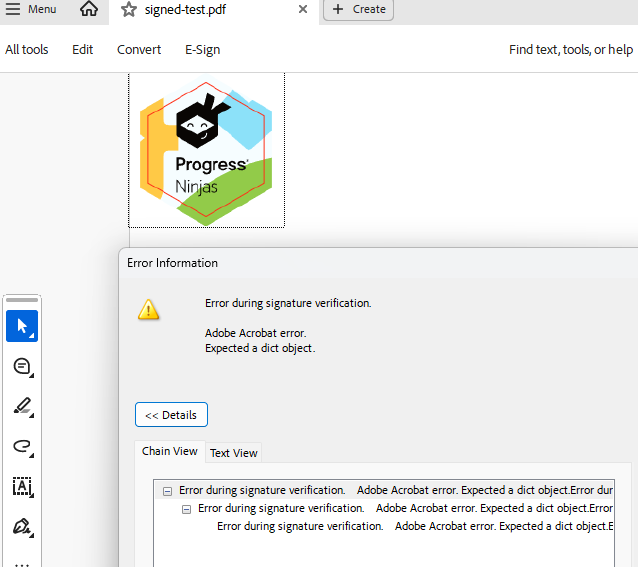
When signing a PDF document with an image using the PdfStreamSigner, the signature is broken. This is the used approach for signing the document: https://www.telerik.com/document-processing-libraries/documentation/libraries/radpdfprocessing/features/digital-signature/pdfstreamsigner
However, instead of using the DrawText method, the DrawImage method is used.
When a worksheet has name that has spaces and a hyperlink to this worksheet is being inserted in Excel, quotes are used to surround the name (ex: 'Sheet 12'!A1) for a valid hyperlink. If quotes are not added, the hyperlink is invalid. In RadSpreadsheet, it is the opposite: (Sheet 12!A1 is correct, while 'Sheet 12'!A1 is incorrect). Thus, opening such an exported document from RadSpreadsheet in Excel loads it with incorrect hyperlinks; and importing such an Excel document in RadSpreadsheet loads it with incorrect hyperlinks. A way to workaround this issue is to modify the hyperlinks on import/export from/to RadSpreadsheet. You can find attached a project demonstrating this approach.
LineInfo objects are not cleared when there are tables in the document being exported to PDF which leads to OutOfMemoryException.
NotImplementedException is thrown for GetCapHeight method of CFFFontSource.
System.NotImplementedException: The method or operation is not implemented.at Telerik.Windows.Documents.Core.Fonts.Type1.CFFFormat.CFFFontSource.GetCapHeight()
at Telerik.Windows.Documents.Core.Fonts.FontSource.get_CapHeight()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Fonts.FontDescriptor.CopyRequiredButType3FontPropertiesFrom(FontBase font)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Fonts.FontDescriptor.CopyPropertiesFrom(IPdfExportContext context, FontBase font)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Fonts.CidFontObject.CopyPropertiesFromOverride(IPdfExportContext context, FontBase font)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Fonts.Type0FontObject.CopyPropertiesFromOverride(IPdfExportContext context, FontBase font)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Export.PdfExporter.WriteFontsFromContext(PdfWriter writer, IPdfExportContext context)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Export.PdfExporter.Export(IRadFixedDocumentExportContext context, Stream output)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.ExceptionHandling.ExecutionHandler.TryHandleExecution[E](Action operation)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.PdfFormatProvider.ExportOverride(RadFixedDocument document, Stream output, CancellationToken cancellationToken)
at Telerik.Windows.Documents.Common.FormatProviders.FormatProviderBase`1.Export(T document, Stream output, Nullable`1 timeout)
Text frames are paragraphs of text in a document which are positioned in a separate region or frame in the document and can be positioned with a specific size and position relative to non-frame paragraphs in the current document. More information about it is available in section 22.9.2.18 ST_XAlign (Horizontal Alignment Location) of Open Office XML.
When table with table border without color set is created (the color is null), and the document is exported to PDF, ArgumentNullException is thrown.
Workaround: Explicitly set a color where the color is null.
private void PdfExport()
{
var tables = this.document.EnumerateChildrenOfType<Table>();
foreach (var table in tables)
{
TableBorders coloredClone = this.CopyTableBorders_SetColorWhenOmitted(table);
table.Borders = coloredClone;
using (Stream output = new FileStream(fileName, FileMode.OpenOrCreate))
{
provider.Export(this.document, output);
}
}
}
private TableBorders CopyTableBorders_SetColorWhenOmitted(Table table)
{
var leftBorder = new Border(table.Borders.Left.Thickness,
table.Borders.Left.Style,
table.Borders.Left.Color ?? new ThemableColor(Colors.Transparent),
table.Borders.Left.Shadow,
table.Borders.Left.Frame,
table.Borders.Left.Spacing);
var rightBorder = new Border(table.Borders.Right.Thickness,
table.Borders.Right.Style,
table.Borders.Right.Color ?? new ThemableColor(Colors.Transparent),
table.Borders.Right.Shadow,
table.Borders.Right.Frame,
table.Borders.Right.Spacing);
var bottomBorder = new Border(table.Borders.Bottom.Thickness,
table.Borders.Bottom.Style,
table.Borders.Bottom.Color ?? new ThemableColor(Colors.Transparent),
table.Borders.Bottom.Shadow,
table.Borders.Bottom.Frame,
table.Borders.Bottom.Spacing);
var topBorder = new Border(table.Borders.Top.Thickness,
table.Borders.Top.Style,
table.Borders.Top.Color ?? new ThemableColor(Colors.Transparent),
table.Borders.Top.Shadow,
table.Borders.Top.Frame,
table.Borders.Top.Spacing);
var insideHorizontalBorder = new Border(table.Borders.InsideHorizontal.Thickness,
table.Borders.InsideHorizontal.Style,
table.Borders.InsideHorizontal.Color ?? new ThemableColor(Colors.Transparent),
table.Borders.InsideHorizontal.Shadow,
table.Borders.InsideHorizontal.Frame,
table.Borders.InsideHorizontal.Spacing);
var insideVerticalBorder = new Border(table.Borders.InsideVertical.Thickness,
table.Borders.InsideVertical.Style,
table.Borders.InsideVertical.Color ?? new ThemableColor(Colors.Transparent),
table.Borders.InsideVertical.Shadow,
table.Borders.InsideVertical.Frame,
table.Borders.InsideVertical.Spacing);
var tableBorders = new TableBorders(leftBorder, topBorder, rightBorder, bottomBorder, insideHorizontalBorder, insideVerticalBorder);
return tableBorders;
}
In DOCX, such lines are defined using the legacy VML definitions:
<w:pict w14:anchorId="324D5836">
<v:rect id="_x0000_i1025" style="width:0;height:1.5pt" o:hralign="center" o:hrstd="t" o:hr="t" fillcolor="#a0a0a0" stroked="f"/>
</w:pict>When importing a document containing an invalid PDF object dictionary key an exception is thrown.
When importing a document with button field with missing type, an error occurs.
51 0 obj << /Kids [ 70 0 R 71 0 R 72 0 R 73 0 R 74 0 R 75 0 R 76 0 R 77 0 R 78 0 R 79 0 R 80 0 R 81 0 R 82 0 R 83 0 R 84 0 R 85 0 R 86 0 R 87 0 R 88 0 R 89 0 R 90 0 R 91 0 R 92 0 R 93 0 R 94 0 R 95 0 R 96 0 R 97 0 R 98 0 R 99 0 R 100 0 R 101 0 R 102 0 R 103 0 R 104 0 R 105 0 R 106 0 R 107 0 R 108 0 R 109 0 R 110 0 R 111 0 R 112 0 R 113 0 R 114 0 R 115 0 R 116 0 R 14 0 R ] /T (Button 70) >> endobj

Workaround: Handle the exception: https://docs.telerik.com/devtools/document-processing/libraries/radpdfprocessing/features/handling-document-exceptions