Hello support team,
We faced an exception that ShadingType 1 is not supported. Can you please confirm that this is expected?
Regards,
Vitalii
This is the code for reproducing the incorrect PDF document. If the step with changing the font is commented, the document is exported properly:
//Step 1: Create an instance of XlsxFormatProvider to import the Excel file
XlsxFormatProvider xlsxFormatProvider = new XlsxFormatProvider();
Telerik.Windows.Documents.Spreadsheet.FormatProviders.Pdf.PdfFormatProvider pdfFormatProvider = new Telerik.Windows.Documents.Spreadsheet.FormatProviders.Pdf.PdfFormatProvider();
Workbook workbook;
using (FileStream input = new FileStream("Input.xlsx", FileMode.Open))
{
workbook = xlsxFormatProvider.Import(input, TimeSpan.FromSeconds(10));
}
//Step 2: Export the workbook to PDF RadFixedDocument to modify fonts
Telerik.Windows.Documents.Spreadsheet.FormatProviders.Pdf.PdfFormatProvider spread_pdf_provider = new Telerik.Windows.Documents.Spreadsheet.FormatProviders.Pdf.PdfFormatProvider();
RadFixedDocument fixedDocument = spread_pdf_provider.ExportToFixedDocument(workbook, TimeSpan.FromSeconds(10));
foreach (var page in fixedDocument.Pages)
{
foreach (var content in page.Content)
{
if (content is TextFragment text)
{
// Replace the font with Helvetica or HelveticaBold based on the original font style
text.Font = text.Font.Name.ToLower().Contains("bold")
? FontsRepository.HelveticaBold
: FontsRepository.Helvetica;
}
}
}
//Step 3: Save the modified RadFixedDocument back to PDF
string outputFileName = "ExportedWorkbook.pdf";
Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.PdfFormatProvider fixed_pdf_provider = new Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.PdfFormatProvider();
using (FileStream output = new FileStream(outputFileName, FileMode.Create))
{
fixed_pdf_provider.ExportSettings.DocumentUnhandledException += ExportSettings_DocumentUnhandledException;
fixed_pdf_provider.ExportSettings.FontEmbeddingType = Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Export.FontEmbeddingType.Subset;
fixed_pdf_provider.Export(fixedDocument, output, TimeSpan.FromSeconds(10));
}
Process.Start(new ProcessStartInfo() { FileName = outputFileName, UseShellExecute = true });
using Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Streaming;
using Telerik.Windows.Documents.Fixed.Model.Editing;
using Telerik.Windows.Documents.Fixed.Model.InteractiveForms;
using Telerik.Windows.Documents.Fixed.Model;
using Telerik.Documents.Primitives;
using System.Diagnostics;
using System.Reflection.Metadata;
using Telerik.Windows.Documents.Fixed.FormatProviders.Pdf;
namespace _1681158PdfInputFields
{
internal class Program
{
static void Main(string[] args)
{
ExportExamplePdfForm();
}
public static void ExportExamplePdfForm()
{
RadFixedDocument fixedDoc = new RadFixedDocument();
RadFixedPage fixedPage = fixedDoc.Pages.AddPage();
FixedContentEditor editor = new FixedContentEditor(fixedPage);
editor.Position.Translate(100, 100);
TextBoxField textBox = new TextBoxField("textBox");
fixedDoc.AcroForm.FormFields.Add(textBox);
textBox.Value = "Sample text...";
Size widgetDimensions = new Size(200, 30);
DrawNextWidgetWithDescription(editor, "TextBox", (e) => e.DrawWidget(textBox, widgetDimensions));
string fileName = "output.pdf";
File.Delete(fileName);
// File.WriteAllBytes(fileName, new PdfFormatProvider().Export(fixedDoc, TimeSpan.FromSeconds(15)));
string ResultFileName = "result.pdf";
File.Delete(ResultFileName);
using (PdfStreamWriter writer = new PdfStreamWriter(File.OpenWrite(ResultFileName)))
{
foreach (RadFixedPage page in fixedDoc.Pages)
{
writer.WritePage(page);
}
}
ProcessStartInfo psi = new ProcessStartInfo()
{
FileName = ResultFileName,
UseShellExecute = true
};
Process.Start(psi);
Console.WriteLine("Document created.");
}
private static void DrawNextWidgetWithDescription(FixedContentEditor editor, string description, Action<FixedContentEditor> drawWidgetWithEditor)
{
double padding = 20;
drawWidgetWithEditor(editor);
Size annotationSize = editor.Root.Annotations[editor.Root.Annotations.Count - 1].Rect.Size;
double x = editor.Position.Matrix.OffsetX;
double y = editor.Position.Matrix.OffsetY;
Block block = new Block();
block.TextProperties.FontSize = 20;
block.VerticalAlignment = Telerik.Windows.Documents.Fixed.Model.Editing.Flow.VerticalAlignment.Center;
block.InsertText(description);
editor.Position.Translate(x + annotationSize.Width + padding, y);
editor.DrawBlock(block, new Size(editor.Root.Size.Width, annotationSize.Height));
editor.Position.Translate(x, y + annotationSize.Height + padding);
}
}
}
The issue may be reproduced by opening the attached PDF in Adobe Reader. Although the viewer initially shows the characters correctly, when you start typing in the TextBox, the umlaut/diacritics characters get corrupted. In other PDF viewers, the umlaut characters are handled correctly, so the issue seems to related to concrete Adobe Reader encoding handling implementation. The diacritic characters are handled incorrectly in other viewers as well (e.g. Chrome).
When importing a document with an invalid creation or modification date, an exception is thrown:
- FormatException: 'The input string '' was not in a correct format.'
- ArgumentOutOfRangeException: 'Year, Month, and Day parameters describe an unrepresentable DateTime.'
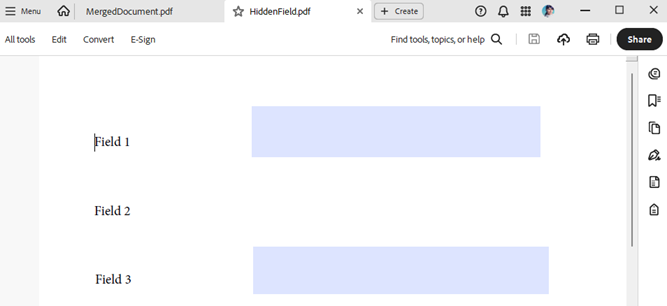
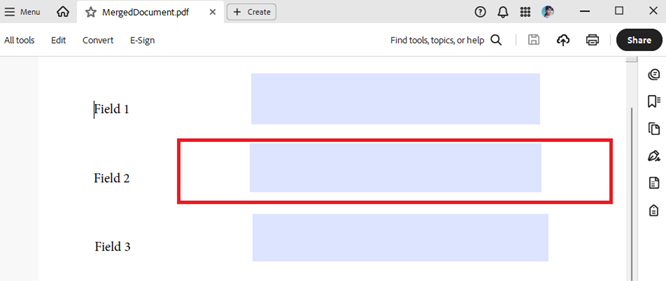
When a Pdf document contains TextBoxFields some of which are hidden and you merge it with another document, the hidden state is reset and the field appears in the merged document:
Before:
After:
System.ArgumentException: 'An item with the same key has already been added. Key: Telerik.Windows.Documents.Fixed.Model.InteractiveForms.RadioButtonField'
It is reproducible when you have at least 2 pages with RadioButtonFields. The import operation goes smoothly. However, merging or removing a page after import leads to the described error.