Setting a filter on a mask results in an invalid file when exporting.
Workaround: Set the filer like this:
PdfFormatProvider provider = new PdfFormatProvider();
provider.ExportSettings.ImageCompression = new ImageFilterTypes[] { ImageFilterTypes.FlateDecode };
The observed result using the WPF PdfViewer:

Workaround: Set explicitly the the ImageCompression filter:
PdfFormatProvider provider = new PdfFormatProvider();
provider.ExportSettings.ImageCompression = new ImageFilterTypes[] { ImageFilterTypes.FlateDecode };When a document containing a SignatureField is exported with the IsEncrypted property set to true, a not set UserPassword is required to open it, which makes it impossible to be opened.
Workaround: Exporting with AES256 encryption does not have this problem:
provider.ExportSettings = new PdfExportSettings
{
IsEncrypted = true,
EncryptionType = EncryptionType.AES256
};
InvalidOperationException Cannot find the "endstream" keyword with a specific file.
According to the PDF Specification:
A stream consists of a dictionary followed by zero or more bytes bracketed between the keywords stream and endstream:
dictionary
stream
… Zero or more bytes …
endstream
This exception seems to be related to AES algorithm PaddingMode property.
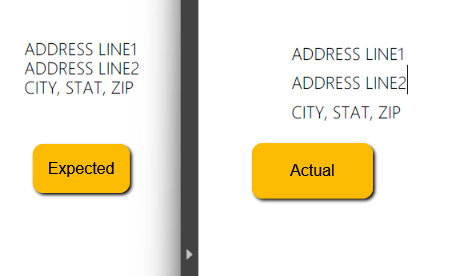
Export should take into account JavaScript and produce PDF similar to the original page.
CryptographicException is thrown when saving with PdfStreamWriter or importing with PdfFormatProvider.
The exception: System.Security.Cryptography.CryptographicException: 'The input data is not a complete block.'
Add a setting that allows enabling printing of protected documents.