Completed
Last Updated:
31 Oct 2022 13:54
by ADMIN
Release R3 2022 SP1
Created by:
Joe
Comments:
0
Category:
PDFViewer
Type:
Bug Report
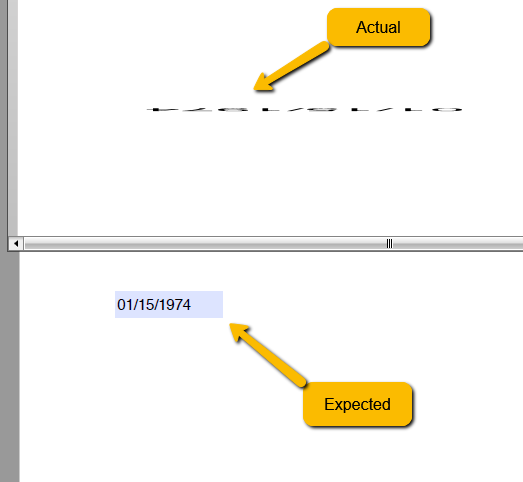
The width height of the tilling drawing is not converted correctly which leads to exception
Completed
Last Updated:
05 Jul 2023 10:51
by ADMIN
Release R2 2023 SP1
Created by:
Sebastien
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Path geometries with a small thickness value are not displayed correctly
Unplanned
Last Updated:
29 Sep 2022 10:57
by Brian
Created by:
Brian
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Some images with SMask applied are not rendered in the viewer.

Unplanned
Last Updated:
27 Sep 2022 07:30
by Hartmut
Created by:
Hartmut
Comments:
0
Category:
PDFViewer
Type:
Bug Report
When the page is rotated the Stamp annotation is not rendered correctly:

Unplanned
Last Updated:
27 Sep 2022 06:36
by Hartmut
Created by:
Hartmut
Comments:
0
Category:
PDFViewer
Type:
Feature Request
From the PDF Specification: "An ink annotation represents a freehand “scribble” composed of one or more disjoint paths. When opened, it displays a pop-up window containing the text of the associated note."

Sometimes the Ink annotations are imported as UnsupportedAnnotation and not displayed as expected. In such cases, the annotations could be removed from the RadFixedPage content in the following manner:
foreach (RadFixedPage page in document.Pages)
{
List<Annotation> inkAnnotations = page.Annotations.Where(a => a.Type == AnnotationType.Ink).ToList();
foreach (Annotation inkAnnotation in inkAnnotations)
{
page.Annotations.Remove(inkAnnotation);
}
}
Completed
Last Updated:
22 Sep 2022 11:22
by ADMIN
Release LIB 2022.3.926 (26 Sep 2022)
Created by:
Patrizio
Comments:
0
Category:
PDFViewer
Type:
Feature Request
From the PDF specification: "The current stroking alpha constant, specifying the constant shape or constant opacity value to be used for stroking operations in the transparent imaging model."
Unplanned
Last Updated:
05 Sep 2022 10:16
by Mauro
Created by:
Mauro
Comments:
0
Category:
PDFViewer
Type:
Bug Report
VS 2022 designer exception when PdfViewer is dragged and dropped from the toolbox.
Unplanned
Last Updated:
18 Aug 2022 14:14
by Jens
Created by:
Jens
Comments:
0
Category:
PDFViewer
Type:
Feature Request
From PDF Specification: "The value of the field dictionary’s Ff entry is an unsigned 32-bit integer containing flags specifying various characteristics of the field. Bit positions within the flag word are numbered from 1 (low-order) to 32 (high-order)."
Field flags common to all field types: ReadOnly, Required, NoExport.
Field flags common to all field types: ReadOnly, Required, NoExport.
Completed
Last Updated:
18 Aug 2022 07:11
by ADMIN
Release LIB 2022.2.822 (22 Aug 2022)
Created by:
Hashitha
Comments:
0
Category:
PDFViewer
Type:
Bug Report
The Field textbox is too large when the field height is limited and the text is not visible when one is typing.
Completed
Last Updated:
15 Jul 2026 14:53
by ADMIN
Created by:
Darcy
Comments:
0
Category:
PDFViewer
Type:
Bug Report
The PdfViewer has slow performance when rendering images that have large size but are scaled down.
Unplanned
Last Updated:
06 Jun 2022 07:27
by Rahul
Created by:
Rahul
Comments:
0
Category:
PDFViewer
Type:
Bug Report
An invalid certificate is not imported correctly and causes exception on export. We should be able to handle this and skip the import without breaking the file.
Unplanned
Last Updated:
07 May 2025 15:15
by Valentin
Created by:
LindenauAtSOG
Comments:
11
Category:
PDFViewer
Type:
Bug Report
When displaying PDF-Files using PDFViewer, ContentElementsCanvas .RenderAsync uses reflection (DispatcherObjectUtils.ApplyDispatcher) to render Visuals on multiple threads.
However this leads to a memory leak since the dispatchers cant be GC'ed, see screenshot below.

The Screenshot is from the actual application we expirienced this issue with, the attached reproduction example is a boiled down version of what your code does.
If you wanna reproduce this on your own, create an application that uses PdfViewer that switches between many pdf files. The ammount of Dispatchers will grow steadily, probably to a total of the number of threads used by Task.Factory.
However this leads to a memory leak since the dispatchers cant be GC'ed, see screenshot below.
The Screenshot is from the actual application we expirienced this issue with, the attached reproduction example is a boiled down version of what your code does.
If you wanna reproduce this on your own, create an application that uses PdfViewer that switches between many pdf files. The ammount of Dispatchers will grow steadily, probably to a total of the number of threads used by Task.Factory.
Unplanned
Last Updated:
19 Apr 2022 12:45
by Dimitar
Created by:
Dimitar
Comments:
0
Category:
PDFViewer
Type:
Feature Request
Implement editor functionalities like add, edit or delete content.
Unplanned
Last Updated:
08 Apr 2022 13:24
by Joe
Created by:
Joe
Comments:
0
Category:
PDFViewer
Type:
Feature Request
When rendering PDF file with a TrueType font and Unicode platform Id (platformId: 0), glyphs are not obtained from CMAP table and are displayed with default rectangle placeholders.
Duplicated
Last Updated:
20 Sep 2022 12:15
by ADMIN
Created by:
Jose Ramon
Comments:
0
Category:
PDFViewer
Type:
Feature Request
Scanned document is not rendered with the new engine
Unplanned
Last Updated:
23 Mar 2022 09:31
by Uma
Created by:
Uma
Comments:
0
Category:
PDFViewer
Type:
Feature Request
This type of dictionary allows users to specify files and define different files for different systems or platforms.
Unplanned
Last Updated:
23 Mar 2022 07:23
by Joseph
Created by:
Joseph
Comments:
0
Category:
PDFViewer
Type:
Bug Report
The image quality is poor when rendering large images.
Completed
Last Updated:
08 Apr 2022 07:29
by ADMIN
Release LIB 2022.1.411 (11 Apr 2022)
Created by:
Bjarke
Comments:
0
Category:
PDFViewer
Type:
Bug Report
The leak is reproducible when printing documents without UI and results in multiple instances of DocumentPrintPresenter kept alive in the memory.
Unplanned
Last Updated:
22 Feb 2022 11:44
by Vojtech
Created by:
Vojtech
Comments:
0
Category:
PDFViewer
Type:
Bug Report
PDFViewer crashes, when used on a tablet, Text selection is activated and text is selected in Touch mode.
Unplanned
Last Updated:
27 Mar 2023 13:52
by ADMIN
ADMIN
Created by:
Martin
Comments:
0
Category:
PDFViewer
Type:
Bug Report
Observed when loading a document: