Recently Updated
Unplanned
Last Updated:
17 Apr 2024 10:05
by ADMIN
Created by:
Chris
Comments:
1
Category:
PdfViewer
Type:
Feature Request
Provide a new property that specifies FileName in SaveAs command.
Declined
Last Updated:
17 Apr 2024 08:22
by ADMIN
ADMIN
Created by:
Hristo
Comments:
1
Category:
PdfViewer
Type:
Feature Request
The issue is reproducible only on Windows XP. On newer versions of windows, the images are rendered as expected. WORKAROUND: You may try implementing custom filter that handles the CMYK scenario. How to implement custom DCTDecode filter is described in this documentation article: https://docs.telerik.com/devtools/winforms/pdfviewer/customize-and-extensibility/customize-pdf-rendering
Duplicated
Last Updated:
26 Feb 2024 11:55
by ADMIN
ADMIN
Created by:
Hristo
Comments:
2
Category:
PdfViewer
Type:
Feature Request
Completed
Last Updated:
11 Aug 2023 04:05
by ADMIN
Created by:
Victor
Comments:
1
Category:
PdfViewer
Type:
Feature Request
Is there a way to load this RadFixedDocument into a RadPdfViewer without writing the document to a file first and then loading it in the viewer?
Workaround:
You can achieve the desired functionality by exporting the RadFixedDocument to a MemoryStream instead of a file in the file system and then load it in the PdfViewer:
RadFixedDocument document = CreateRadFixedDocument();
PdfFormatProvider pdfFormatProvider = new PdfFormatProvider();
Stream ms = new MemoryStream();
pdfFormatProvider.Export(document, ms);
radPdfViewer1.LoadDocument(ms);
Completed
Last Updated:
07 Jun 2023 10:39
by ADMIN
Release R2 2023 (2023.2.606)
ADMIN
Created by:
Dess | Tech Support Engineer, Principal
Comments:
0
Category:
PdfViewer
Type:
Feature Request
According to PDF format specification, there are three valid encoding name values (MacRomanEncoding, MacExpertEncoding and WinAnsiEncoding). There are documents that instead of skipping the optional Encoding property, are writing invalid /NULL name value in the font dictionary. Currently, in this invalid document scenario RadPdfViewer throws and catches Exception and this results in missing text content. We may handle this invalid document scenario by ignoring the invalid Encoding value.
Unplanned
Last Updated:
08 May 2023 07:17
by ADMIN
Created by:
Christopher
Comments:
1
Category:
PdfViewer
Type:
Feature Request
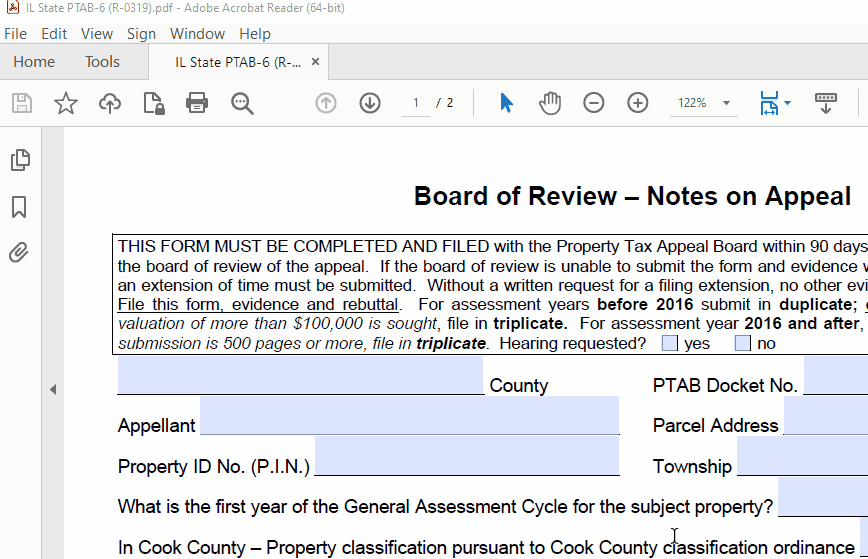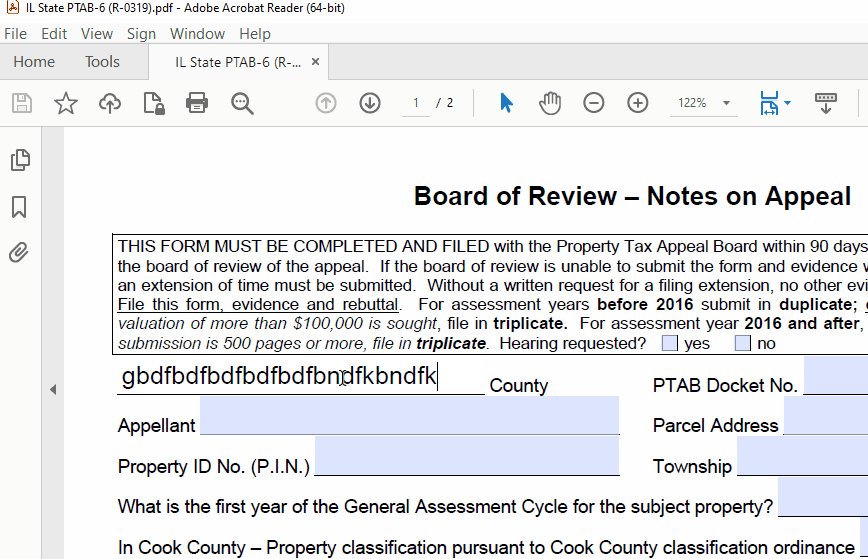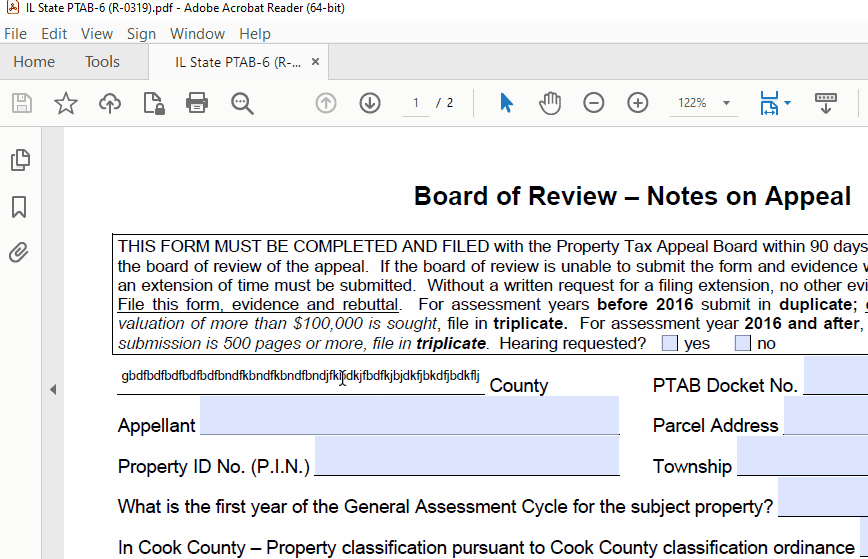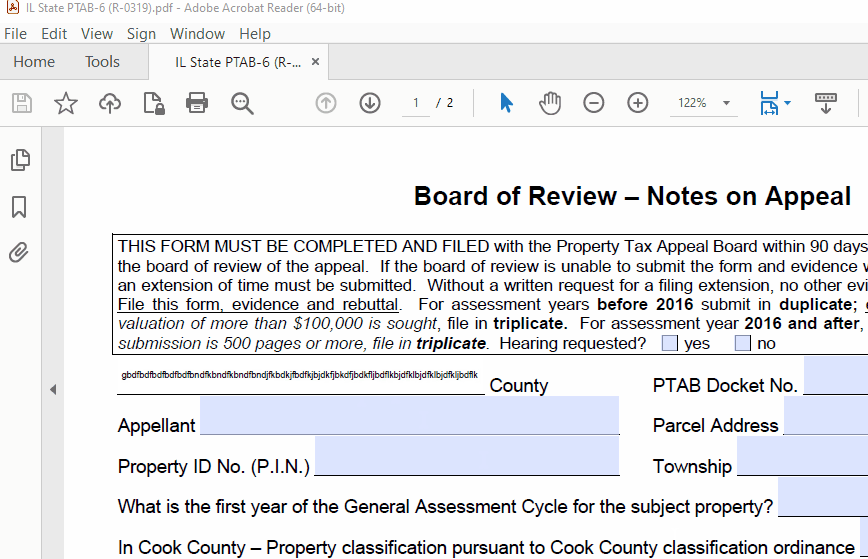
Add functionality for a PDF form filler that supports text auto-sizing/shrinking like Adobe:
Unplanned
Last Updated:
27 Apr 2023 11:39
by Gurmeet
Created by:
Gurmeet
Comments:
0
Category:
PdfViewer
Type:
Feature Request
Introduce locking a document opened in viewer.
Unplanned
Last Updated:
07 Mar 2023 08:08
by Ken
Created by:
Ken
Comments:
0
Category:
PdfViewer
Type:
Feature Request
Expose API that allows you to access the current editor. Perhaps add some events to the EditingFields class.
Unplanned
Last Updated:
21 Dec 2022 07:04
by Joaquin
Created by:
Joaquin
Comments:
0
Category:
PdfViewer
Type:
Feature Request
Add support for XFA fields
Unplanned
Last Updated:
15 Dec 2022 06:33
by Prafull
Created by:
Prafull
Comments:
0
Category:
PdfViewer
Type:
Feature Request
Add support for highlight annotations
Declined
Last Updated:
27 Sep 2022 08:48
by ADMIN
Created by:
Selim
Comments:
1
Category:
PdfViewer
Type:
Feature Request
Hi,
Is there a way to get version and producer metadata from imported PDF files?
Here is how it looks in AdobeReader

Thanks in advance,
Completed
Last Updated:
26 Sep 2022 12:36
by ADMIN
Release R2 2022
ADMIN
Created by:
Tanya
Comments:
2
Category:
PdfViewer
Type:
Feature Request
Completed
Last Updated:
29 Nov 2021 16:38
by ADMIN
Release R1 2022
Created by:
Shreya
Comments:
0
Category:
PdfViewer
Type:
Feature Request
Please refer to the attached gif file and notice the loading delay when scrolling to a specific page. It would be nice to optimize this experience.
Completed
Last Updated:
14 Sep 2021 06:56
by ADMIN
ADMIN
Created by:
Stefan
Comments:
10
Category:
PdfViewer
Type:
Feature Request
Import documents that use this type of encryption. Currently, a handled NotSupportedEncryptionException with message "The encryption method with code 5 is not supported." is thrown while importing such a document.
Unplanned
Last Updated:
11 Jun 2021 09:05
by ADMIN
Created by:
Jan Brandenburger
Comments:
4
Category:
PdfViewer
Type:
Feature Request
An implementation of JPXDecoder should be created to allow the decompression of data encoded using the wavelet-based JPEG2000 standard.
Completed
Last Updated:
07 May 2021 11:46
by ADMIN
Release R2 2021
Created by:
Patrick
Comments:
0
Category:
PdfViewer
Type:
Feature Request
One should be able to change the default SignSignatureDialog. Its buttons event handlers should be made virtual as so one can override the default behavior as well.
Unplanned
Last Updated:
08 Apr 2021 08:06
by ADMIN
Created by:
Joseph
Comments:
0
Category:
PdfViewer
Type:
Feature Request
Introduce support for per page rotation. The result should be automatically saved as well.
Unplanned
Last Updated:
31 Mar 2021 11:20
by ADMIN
Created by:
Henk
Comments:
0
Category:
PdfViewer
Type:
Feature Request
The PDF model allows actions to be defined for widgets using the optional /A entry.
Unplanned
Last Updated:
05 Mar 2021 12:14
by ADMIN
Created by:
Ole
Comments:
0
Category:
PdfViewer
Type:
Feature Request
According to the PDF specification: Codes are never longer than 12 bits; therefore, entry 4095 is the last entry of the LZW table.
Completed
Last Updated:
19 Feb 2021 10:21
by ADMIN
Release R3 2020
ADMIN
Created by:
Hristo
Comments:
0
Category:
PdfViewer
Type:
Feature Request
This is Unicode (UTF-16BE) encoding for the Adobe-GB1 character collection; contains mappings for all characters in the GB18030-2000 character set. Described on page 443 in Pdf Reference 1.7.