An exception is thrown when loading a document:
FileNotFoundException: Could not load file or assembly 'Microsoft.Web.WebView2.WinForms, Version=1.0.3719.77, Culture=neutral, PublicKeyToken=2a8ab48044d2601e' or one of its dependencies. The system cannot find the file specified.
In the following scenario, the item's text in the drop-down list shows different text from the selected item.
When the document is open in a web browser :

When the document is open in the RadPdfViewer control.
Editor open and editor closed:


In the following case, we have a document with hyperlinks that scroll to a specific location in the document. Clicking on the links does not scroll to the specified location.
When using DFKai-SB , the glyphs are not rendered like in Adobe or the browser:
Adobe:
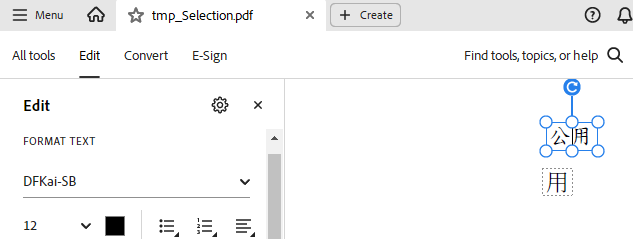
PdfViewer:
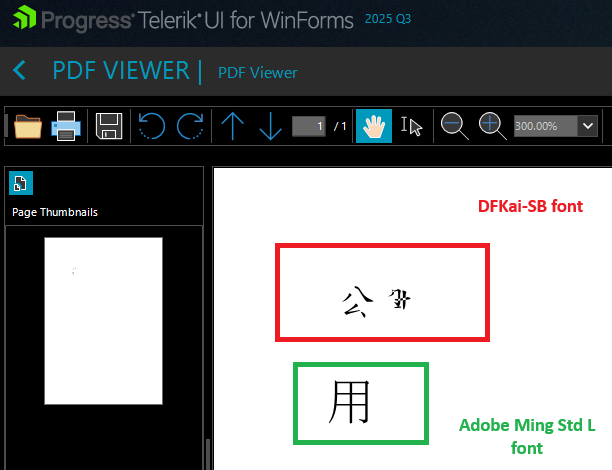
Overview
This repository documents a bug found in the Telerik PDF Viewer control for Windows Forms. The issue specifically affects the rendering of SVG graphics embedded in PDF files, where the stroke-width attribute is ignored by the viewer.
Affected Component
- Product: Telerik UI for WinForms
- Control: `RadPdfViewer'
- Version: 2025.01
- Platform: Windows Forms (.NET Framework)
Description of the Issue
When a PDF file contains an embedded SVG graphic that utilizes the stroke-width CSS property (or SVG attribute), the stroke width is not rendered correctly in Telerik's PDF preview control. Regardless of:
- Unit used (e.g., px, pt, em, %, etc.)
- Value assigned (e.g.,
stroke-width: 5,stroke-width: 30, etc.)
…the resulting line always appears thin, as if the stroke width were ignored entirely. This makes the SVG appear incorrectly and inconsistent with its rendering in other PDF viewers (e.g., Adobe Acrobat, Chrome's built-in viewer).
Steps to Reproduce
- Run the application from provided MCVE
- Observe the SVG lines in PDF preview: all strokes appear thin, regardless of defined stroke width.
Expected Behavior
The Telerik PDF viewer should correctly honor and render the stroke-width property defined within SVG elements embedded in the PDF file.
Actual Behavior
All strokes in SVGs appear very thin, with no visual difference despite varying stroke widths in the source SVG.
Sample Files
- ✅
_PdfExample.pdf: A PDF with SVG lines that render correctly in Microsoft Edge. - ✅
_PdfExample.pdf: Screenshot of how the PDF file looks in Microsoft Edge. - ❌
_ScreenshotFromTelerik.png: Screenshot of how the same file looks in the Telerik PDF Viewer (note the thin lines). - 🔍
_LargeStroke.svg,_SmallStroke.svg: The original SVGs used in the PDF file.
Environment
| Component | Version |
|---|---|
| Telerik UI | 2025.1.211.48 |
| .NET Framework | .NET Framework 4.8 |
| OS | Windows 11 |
Suggested Fix
Ensure that the rendering engine used by RadPdfViewer fully supports the SVG stroke-width attribute when parsing and rendering embedded SVG content.
Template PDF documents created for example with Foxit PDF Editor, or with documents created programmatically with Aspose.
If the documents are opened with other PDF viewers such as Foxit or Adobe, there are no problems, which is not the case with the Telerik viewer.
I am currently using Telerik UI for WinForms 2024 Q4 24.4.1113.0

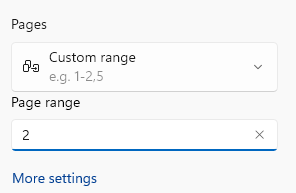
For example, if you choose to print second page like this:
It prints only the first page of the document, instead of the second page.
Currently, RadPdfViewer offers the DataError event which is purposed to handle errors during the import process. However, if there are problematic pages that are rendered in the viewer at a later moment after the document is already imported, the viewer doesn't offer a suitable way for handling such problematic moments even though the PdfProcessing library throws one of its exceptions.
The exact client's case is loading a PDF document which contains images requiring JPX Decoder which is currently not supported. Even though the PdfProcessing library throws internally the following error, the RadPdfViewer control doesn't throw the DataError event with the respective error:
Telerik.Windows.Documents.Fixed.Exceptions.NotSupportedFilterException: 'JPXDecode is not supported.'
The following assemblies are missing in the 2024_4_1127_Dev_Preview zip folder:
- Telerik.Windows.Documents.Flow.FormatProviders.Doc
- Telerik.Windows.Documents.Flow.FormatProviders.Pdf
- Telerik.Documents.SpreadsheetStreaming.dll
Open the Demo app and load the PDF document with such annotation. The following error occurs:
************** Exception Text **************System.Collections.Generic.KeyNotFoundException: The given key was not present in the dictionary.
at System.Collections.Generic.Dictionary`2.get_Item(TKey key)
at Telerik.Windows.Documents.Fixed.Utilities.Rendering.Annotations.DefaultAppearanceProvider.TryGetCurrentAnnotationAppearances(Annotation annotation, SingleStateAppearances& singleStateAppearances)
at Telerik.Windows.Documents.Fixed.Utilities.Rendering.Annotations.DefaultAppearanceProvider.TryProvideAppearanceOverride(Annotation annotation, AnnotationAppearanceMode annotationAppearanceMode, FormSource& formSource)
at Telerik.Windows.Documents.Fixed.Utilities.Rendering.Annotations.BaseAppearanceProvider.TryProvideAppearance(Annotation annotation, AnnotationAppearanceMode annotationAppearanceMode, FormSource& appearance)
at Telerik.Windows.Documents.Fixed.Utilities.Rendering.Annotations.BaseAppearanceProvider.TryProvideAppearance(Annotation annotation, AnnotationAppearanceMode annotationAppearanceMode, FormSource& appearance)
at Telerik.WinControls.PdfViewer.FixedPageRenderer.DrawPage(RadFixedPage page, Graphics graphics)
at Telerik.WinControls.UI.FixedPagePreRenderer.rendererWorker_DoWork(Object sender, DoWorkEventArgs e)
at System.ComponentModel.BackgroundWorker.OnDoWork(DoWorkEventArgs e)
at System.ComponentModel.BackgroundWorker.WorkerThreadStart(Object argument)
The problem I'm trying to solve is that users do not know that the original document may not be what they are seeing in the viewer when there are layers.
A property that indicates
that a document has layers would allow the system to refuse to open the document.