static void Main(string[] args)
{
Telerik.Windows.Documents.Flow.Model.RadFlowDocument document = CreateDocument();
Telerik.Windows.Documents.Flow.FormatProviders.Docx.DocxFormatProvider provider = new Telerik.Windows.Documents.Flow.FormatProviders.Docx.DocxFormatProvider();
string outputFilePath = "output.docx";
File.Delete(outputFilePath);
using (Stream output = File.OpenWrite(outputFilePath))
{
provider.Export(document, output, TimeSpan.FromSeconds(10));
}
Process.Start(new ProcessStartInfo() { FileName = outputFilePath, UseShellExecute = true });
}
//Not working example
private static RadFlowDocument CreateDocument()
{
int FullPercentWidth = 100;
var document = new RadFlowDocument();
var editor = new RadFlowDocumentEditor(document);
editor.InsertSection();
var header = document.Sections.First().Headers.Add().Blocks.AddParagraph();
header.TextAlignment = Alignment.Center;
editor.MoveToParagraphStart(header);
editor.InsertLine("Dissemination Label");
var br = new Break(document);
header.Inlines.Add(br);
editor.MoveToParagraphEnd(header);
editor.InsertText("Test");
editor.MoveToParagraphStart(document.Sections.First().Blocks.AddParagraph());
editor.InsertParagraph();
editor.InsertLine("First Header");
editor.InsertLine("Second Header");
editor.TableFormatting.StyleId = BuiltInStyleNames.TableGridStyleId;
document.StyleRepository.AddBuiltInStyle(BuiltInStyleNames.TableGridStyleId);
Table table = editor.InsertTable();
table.PreferredWidth = new TableWidthUnit(TableWidthUnitType.Percent, FullPercentWidth);
table.LayoutType = TableLayoutType.AutoFit;
TableRow headerRow = table.Rows.AddTableRow();
var cell = headerRow.Cells.AddTableCell();
var cellParagraph = cell.Blocks.AddParagraph();
_ = cellParagraph.Inlines.AddRun("ID");
var cell2 = headerRow.Cells.AddTableCell();
var cellParagraph2 = cell2.Blocks.AddParagraph();
_ = cellParagraph2.Inlines.AddRun("Title");
var cell3 = headerRow.Cells.AddTableCell();
var cellParagraph3 = cell3.Blocks.AddParagraph();
_ = cellParagraph3.Inlines.AddRun("Page Number");
for (var i = 0; i < 3; i++)
{
var dataRow = table.Rows.AddTableRow();
string id = "ID-" + i;
var cell4 = dataRow.Cells.AddTableCell();
var cellParagraph4 = cell4.Blocks.AddParagraph();
_ = cellParagraph4.Inlines.AddRun(id);
var cell5 = dataRow.Cells.AddTableCell();
var cellParagraph5 = cell5.Blocks.AddParagraph();
_ = cellParagraph5.Inlines.AddRun($"Fake Title {i}");
var cell6 = dataRow.Cells.AddTableCell();
var cellParagraph6 = cell6.Blocks.AddParagraph();
editor.MoveToParagraphStart(cellParagraph6);
editor.InsertField($"PAGEREF bookmark-{id}", string.Empty);
}
for (var i = 0; i < 3; i++)
{
var id = "ID-" + i;
var section = document.Sections.AddSection();
section.SectionType = SectionType.NextPage;
var header2 = document.Sections.Count == 1
? document.Sections.AddSection().Headers.Add().Blocks.AddParagraph()
: document.Sections.Last().Headers.Add().Blocks.AddParagraph();
editor.MoveToParagraphStart(header2);
editor.InsertLine("Dissemination Label");
editor.InsertBreak(BreakType.LineBreak);
editor.InsertLine("Fake Header");
editor.InsertText("Display name");
var table2 = new Table(document)
{
PreferredWidth = new TableWidthUnit(TableWidthUnitType.Percent, FullPercentWidth),
LayoutType = TableLayoutType.AutoFit
};
var headerRow2 = table2.Rows.AddTableRow();
headerRow2.CanSplit = false;
var headerCell = headerRow2.Cells.AddTableCell();
var headerParagraph = headerCell.Blocks.AddParagraph();
headerParagraph.Inlines.AddRun("Title").FontWeight = FontWeights.Bold;
headerParagraph.Spacing.SpacingAfter = 0;
headerCell.ColumnSpan = 3;
table2.LayoutType = TableLayoutType.FixedWidth;
var row = InsertRow(table2);
var cell7 = row.Cells.AddTableCell();
var cellParagraph7 = cell7.Blocks.AddParagraph();
_ = cellParagraph7.Inlines.AddRun("Stuff and things");
var cell8 = row.Cells.AddTableCell();
var cellParagraph8 = cell8.Blocks.AddParagraph();
_ = cellParagraph8.Inlines.AddRun($"Stuff and things-{id}");
editor.InsertBookmark($"bookmark-{id}");
_ = InsertRow(table2);
_ = InsertRow(table2);
document.Sections.Last().Blocks.Add(table2);
var table3 = new Table(document)
{
PreferredWidth = new TableWidthUnit(TableWidthUnitType.Percent, FullPercentWidth),
LayoutType = TableLayoutType.AutoFit
};
var fakeText = "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed laoreet finibus nulla sit amet consectetur. Fusce dignissim sapien congue augue hendrerit, eu rutrum orci lacinia. Maecenas sit amet augue ut arcu consequat molestie ac pretium nulla. Donec venenatis rhoncus pulvinar. Aliquam vel est vitae lacus porta aliquam. Morbi aliquet vulputate turpis, ut vulputate elit accumsan at. Vivamus interdum dictum arcu vel euismod. Curabitur commodo eu nisi ut ultrices. Duis at auctor eros. Vivamus et metus ligula. Vestibulum feugiat velit a feugiat sodales. Sed vitae urna sodales, faucibus felis non, sagittis diam.\r\n\r\nPraesent turpis est, aliquet consectetur felis et, pharetra placerat ipsum. Sed at consectetur metus. Integer dictum iaculis libero, interdum vehicula ipsum convallis a. Orci varius natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Sed pretium ac quam id finibus. Maecenas bibendum magna vel rhoncus eleifend. Etiam nec ante nulla. Etiam lacinia vulputate quam, et ullamcorper magna fermentum quis. Suspendisse potenti. Quisque quis nulla non velit lacinia laoreet. Fusce et lacinia enim, sit amet rhoncus eros. Etiam placerat fringilla nibh ac commodo.\r\n\r\nMorbi ac commodo elit. Sed a leo quis sem convallis volutpat eget et nunc. In laoreet eleifend ullamcorper. Phasellus pharetra molestie eleifend. Cras consequat risus ac est accumsan sagittis. Suspendisse facilisis ultrices ipsum, vitae porttitor augue tincidunt ac. Ut sagittis nisl tristique efficitur aliquam. Pellentesque molestie mauris id ipsum lacinia, a vehicula eros molestie. Aliquam quis sagittis tellus.";
for (var j = 0; j < 2; j++)
{
var row2 = InsertRow(table3);
var cell9 = row2.Cells.AddTableCell();
var cellParagraph9 = cell9.Blocks.AddParagraph();
_ = cellParagraph9.Inlines.AddRun(fakeText);
}
document.Sections.Last().Blocks.Add(table3);
}
FlowExtensibilityManager.NumberingFieldsProvider = new NumberingFieldsProvider();
foreach (var s in document.Sections)
{
s.Footers.Add();
Footer f = s.Footers.Default;
Paragraph paragraph = f.Blocks.AddParagraph();
paragraph.TextAlignment = Alignment.Right;
editor.MoveToParagraphStart(paragraph);
editor.InsertText("Page ");
editor.InsertField("PAGE", string.Empty);
editor.InsertText(" of ");
editor.InsertField("NUMPAGES", string.Empty);
var paragrpah2 = s.Blocks.AddParagraph();
editor.MoveToParagraphStart(paragrpah2);
}
document.UpdateFields();
return document;
}
private static TableRow InsertRow(Table table)
{
TableRow row = new TableRow(table.Document);
table.Rows.Add(row);
return row;
}When exporting a PDF page to an image with the SkiaImageFormatProvider the following error occurs:
System.IndexOutOfRangeException: 'Index was outside the bounds of the array.'

Error message:
System.InvalidCastException: 'Unable to cast object of type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Forms.FormFieldsTree' to type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfArray'.'Error message:
System.InvalidCastException: 'Unable to cast object of type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfArray' to type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Functions.FunctionObject'.'Import the following HTML content and export it to DOCX format:
<p>Here is my list</p>
<ol start="108" style="list-style-type: lower-latin;">
<li>Item 1</li>
<li>Item 2</li>
</ol>Expected result:

Actual result:

When converting HTML to DOCX, margins set on an HTML element are ignored. These styles are exported correctly when the HTML passed to the converter is formatted with indents. The following XUnit test demonstrates this behavior with a simplified example.
using Telerik.Windows.Documents.Flow.FormatProviders.Docx;
using Telerik.Windows.Documents.Flow.FormatProviders.Html;
namespace MSPI.Tests.Unit;
public class WordExportTest
{
[Fact]
public async Task TextExport()
{
const string formattedDocumentSavePath = @"C:\Testing\export-test-formatted.docx";
const string formattedContent = """"
<p>Test paragraph</p>
<ol style="margin-left: 100px;">
<li>Item 1</li>
<li>Item 2</li>
</ol>
"""";
const string minifiedDocumentSavePath = @"C:\Testing\export-test-minified.docx";
const string minifiedContent = """"<p>Test paragraph</p><ol style="margin-left: 100px;"><li>Item 1</li><li>Item 2</li></ol>"""";
var htmlFormatProvider = new HtmlFormatProvider();
var docxFormatProvider = new DocxFormatProvider();
await using var minifiedDocumentMemoryStream = new MemoryStream();
var minifiedRadFlowDocument = htmlFormatProvider.Import(minifiedContent, TimeSpan.FromSeconds(30));
docxFormatProvider.Export(minifiedRadFlowDocument, minifiedDocumentMemoryStream, TimeSpan.FromSeconds(30));
var minifiedBytes = minifiedDocumentMemoryStream.ToArray();
await File.WriteAllBytesAsync(minifiedDocumentSavePath, minifiedBytes);
await using var formattedDocumentMemoryStream = new MemoryStream();
var formattedRadFlowDocument = htmlFormatProvider.Import(formattedContent, TimeSpan.FromSeconds(30));
docxFormatProvider.Export(formattedRadFlowDocument, formattedDocumentMemoryStream, TimeSpan.FromSeconds(30));
var formattedBytes = formattedDocumentMemoryStream.ToArray();
await File.WriteAllBytesAsync(formattedDocumentSavePath, formattedBytes);
}
}The minified HTML produces the following document:
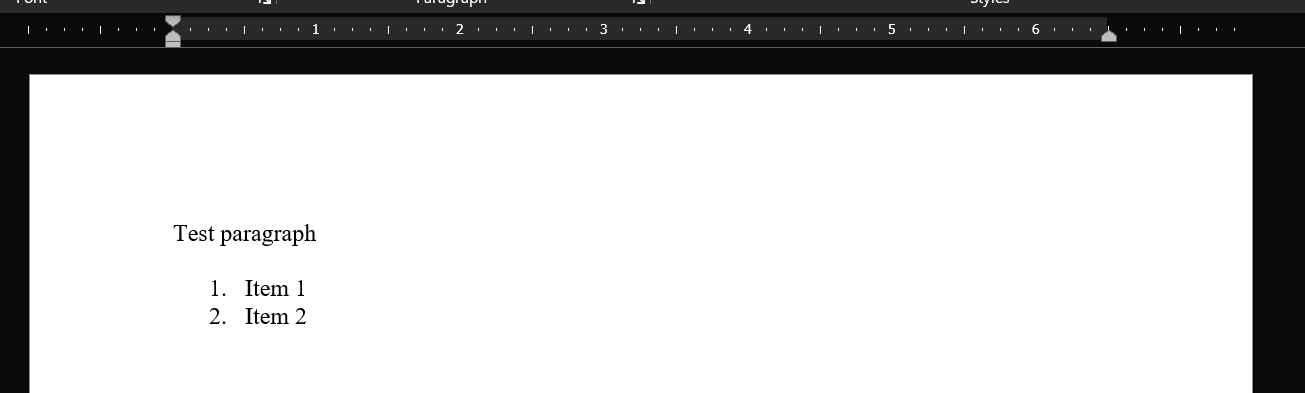
The formatted HTML produces the following document:

string inputFileName = "input.xlsx";
if (!File.Exists(inputFileName))
{
throw new FileNotFoundException(String.Format("File {0} was not found!", inputFileName));
}
Telerik.Windows.Documents.Spreadsheet.Model.Workbook workbook;
IWorkbookFormatProvider formatProvider = new Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.XlsxFormatProvider();
using (Stream input = new FileStream(inputFileName, FileMode.Open))
{
workbook = formatProvider.Import(input, TimeSpan.MaxValue);
}
string outputFilePath = "output.xlsx";
using (Stream output = new FileStream(outputFilePath, FileMode.Create))
{
formatProvider.Export(workbook, output, TimeSpan.MaxValue);
}
Process.Start(new ProcessStartInfo() { FileName = outputFilePath, UseShellExecute = true });Read the documentation for CancelationTokenSource.CancelAfter:
this method will throw an ArgumentOutOfRangeException when: delay.TotalMilliseconds is less than -1 or greater than Int32.MaxValue (or UInt32.MaxValue - 1 on some versions of .NET). Note that this upper bound is more restrictive than TimeSpan.MaxValue.
----------------------------------------------------
your code in CancelationTokenSourceFactory.CreateTokenSource does this check:
if (timeSpan.HasValue && timeSpan.Value != TimeSpan.MaxValue)this check for TimeSpan.MaxValue seems totally pointless here, if timeSpan is anything between ~2147483647 and 922337203685476 milliseconds long this will still just throw a ArgumentOutOfRangeException.
I suspect that this check was intended as a way to prevent creating a cancellation timer that never triggers in the CancellationTokenSource, which should look like this:
if (timeSpan.HasValue && timeSpan != Timeout.InfiniteTimeSpan) //Timeout.InfiniteTimeSpan is -1 millisecondsNullReferenceException when inserting a document containing a table with a document variable having a line break (\n) in its value.