Error message:
System.InvalidCastException: 'Unable to cast object of type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Forms.FormFieldsTree' to type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfArray'.'Error message:
System.InvalidCastException: 'Unable to cast object of type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfArray' to type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Functions.FunctionObject'.'using Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Streaming;
using Telerik.Windows.Documents.Fixed.Model.Editing;
using Telerik.Windows.Documents.Fixed.Model.InteractiveForms;
using Telerik.Windows.Documents.Fixed.Model;
using Telerik.Documents.Primitives;
using System.Diagnostics;
using System.Reflection.Metadata;
using Telerik.Windows.Documents.Fixed.FormatProviders.Pdf;
namespace _1681158PdfInputFields
{
internal class Program
{
static void Main(string[] args)
{
ExportExamplePdfForm();
}
public static void ExportExamplePdfForm()
{
RadFixedDocument fixedDoc = new RadFixedDocument();
RadFixedPage fixedPage = fixedDoc.Pages.AddPage();
FixedContentEditor editor = new FixedContentEditor(fixedPage);
editor.Position.Translate(100, 100);
TextBoxField textBox = new TextBoxField("textBox");
fixedDoc.AcroForm.FormFields.Add(textBox);
textBox.Value = "Sample text...";
Size widgetDimensions = new Size(200, 30);
DrawNextWidgetWithDescription(editor, "TextBox", (e) => e.DrawWidget(textBox, widgetDimensions));
string fileName = "output.pdf";
File.Delete(fileName);
// File.WriteAllBytes(fileName, new PdfFormatProvider().Export(fixedDoc, TimeSpan.FromSeconds(15)));
string ResultFileName = "result.pdf";
File.Delete(ResultFileName);
using (PdfStreamWriter writer = new PdfStreamWriter(File.OpenWrite(ResultFileName)))
{
foreach (RadFixedPage page in fixedDoc.Pages)
{
writer.WritePage(page);
}
}
ProcessStartInfo psi = new ProcessStartInfo()
{
FileName = ResultFileName,
UseShellExecute = true
};
Process.Start(psi);
Console.WriteLine("Document created.");
}
private static void DrawNextWidgetWithDescription(FixedContentEditor editor, string description, Action<FixedContentEditor> drawWidgetWithEditor)
{
double padding = 20;
drawWidgetWithEditor(editor);
Size annotationSize = editor.Root.Annotations[editor.Root.Annotations.Count - 1].Rect.Size;
double x = editor.Position.Matrix.OffsetX;
double y = editor.Position.Matrix.OffsetY;
Block block = new Block();
block.TextProperties.FontSize = 20;
block.VerticalAlignment = Telerik.Windows.Documents.Fixed.Model.Editing.Flow.VerticalAlignment.Center;
block.InsertText(description);
editor.Position.Translate(x + annotationSize.Width + padding, y);
editor.DrawBlock(block, new Size(editor.Root.Size.Width, annotationSize.Height));
editor.Position.Translate(x, y + annotationSize.Height + padding);
}
}
}
Corrupted document when exporting "Courier New" subset.
Workaround - fully embed the font:
var pdfFormatProvider = new PdfFormatProvider();
pdfFormatProvider.ExportSettings.FontEmbeddingType = FontEmbeddingType.Full;
PdfStreamWriter: "InvalidOperationException: 'isContentReleased'" is thrown when creating a multi-page document with an umlaut on the last page.
Workaround - Explicitly set the block font:block.TextProperties.Font = FontsRepository.Courier;
This is the code for inserting the image:
static void Main(string[] args)
{
FixedExtensibilityManager.ImagePropertiesResolver = new ImagePropertiesResolver();
//Telerik.Windows.Documents.Extensibility.JpegImageConverterBase defaultJpegImageConverter = new Telerik.Documents.ImageUtils.JpegImageConverter();
//Telerik.Windows.Documents.Extensibility.FixedExtensibilityManager.JpegImageConverter = defaultJpegImageConverter;
//Output("fyb-64.png", "output-working.pdf");
Output("fyb.png", "output-broken.pdf");
}
private static void Output(string resourceName, string outputFileName)
{
var document = new RadFixedDocument();
using (var editor = new RadFixedDocumentEditor(document))
{
Stream image = new FileStream(resourceName, FileMode.Open);
var table = new Table
{
LayoutType = TableLayoutType.FixedWidth,
Margin = new Thickness(10, 0, 0, 0),
};
var row = table.Rows.AddTableRow();
var cell = row.Cells.AddTableCell();
var block = cell.Blocks.AddBlock();
block.InsertImage(image);
editor.InsertTable(table);
var pdfData = ExportToPdf(document);
File.Delete(outputFileName);
File.WriteAllBytes(outputFileName, pdfData);
Process.Start(new ProcessStartInfo() { FileName = outputFileName, UseShellExecute = true });
}
}
private static byte[] ExportToPdf(RadFixedDocument document)
{
byte[] pdfData;
using (var ms = new MemoryStream())
{
var pdfFormatProvider = new PdfFormatProvider();
pdfFormatProvider.Export(document, ms);
pdfData = ms.ToArray();
}
return pdfData;
}
Workaround: Instead of setting the ImagePropertiesResolver, set the JpegImageConverter:
Telerik.Windows.Documents.Extensibility.JpegImageConverterBase defaultJpegImageConverter = new Telerik.Documents.ImageUtils.JpegImageConverter();
Telerik.Windows.Documents.Extensibility.FixedExtensibilityManager.JpegImageConverter = defaultJpegImageConverter;
Search for specific text in a PDF document and you will notice that if the document is landscape, the SearchResult.GetWordBoundingRect method may return incorrect results. If the document is Portrait, the exact results are highlighted with the code snippet below:
PdfFormatProvider provider = new PdfFormatProvider();
RadFixedDocument document = provider.Import(File.ReadAllBytes("Landscape.pdf"));
TextSearch searchText = new TextSearch(document);
TextSearchOptions searchOptions = new TextSearchOptions { UseRegularExpression=false, CaseSensitive=false, WholeWordsOnly = true };
IEnumerable<SearchResult> matchResults = searchText.FindAll("sed", searchOptions);
foreach (SearchResult resultItem in matchResults)
{
Rect rect = resultItem.GetWordBoundingRect();
RadFixedPage page = resultItem.GetResultPage();
FixedContentEditor editor = new FixedContentEditor(page);
editor.GraphicProperties.FillColor = new RgbColor(125, 255, 0, 0);
editor.DrawRectangle(rect);
}
string outputFilePath = "result.pdf";
File.Delete(outputFilePath);
File.WriteAllBytes(outputFilePath, provider.Export(document));
Process.Start(new ProcessStartInfo() { FileName = outputFilePath, UseShellExecute = true });Landscape: wrong rectangles are highlighted

Portrait: correct rectangles are highlighted:

NullReferenceException is thrown when Find API is used on a newly created document.
Workaround: Export - Import the document before using the Find API
PdfFormatProvider pdfFormatProvider = new PdfFormatProvider();
byte[] exportedDocument = pdfFormatProvider.Export(document);
document = pdfFormatProvider.Import(exportedDocument);
Encoding table headers are preserved when creating subsets.
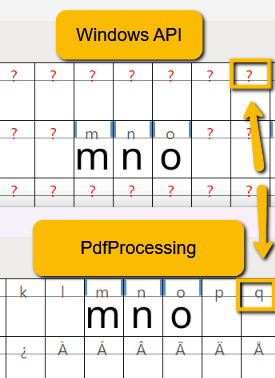
As a result of the below missing operator, some of the glyphs can't be extracted from the CFFFontTable and the characters are not displayed in the PdfViewer:
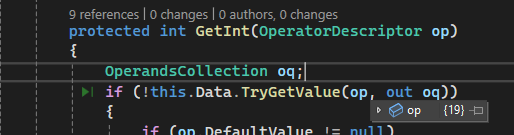
The end user result is missing letter from the PDF content.