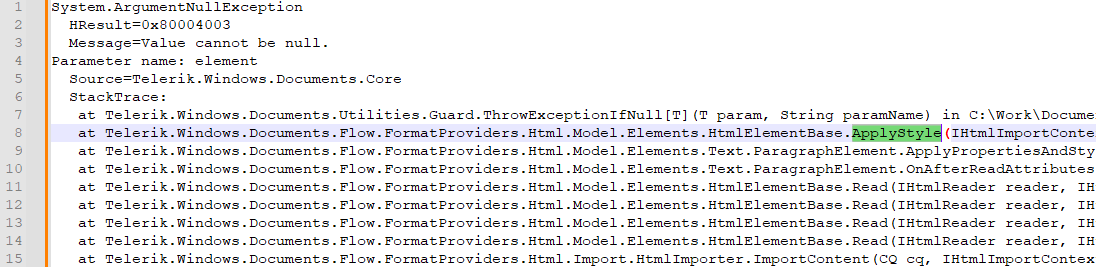
This is the code snippet that reproduces the error:
RadFlowDocument flowDocument = new RadFlowDocument();
RadFlowDocumentEditor editor = new RadFlowDocumentEditor(flowDocument);
Bookmark bookmark = new Bookmark(flowDocument, "Name");
editor.InsertInline(bookmark.BookmarkRangeStart);
Table table = editor.InsertTable(1, 2);
TableCell cell1 = table.Rows[0].Cells[0];
Paragraph cell_paragraph1 = cell1.Blocks.AddParagraph();
editor.MoveToParagraphStart(cell_paragraph1);
editor.InsertText("cell content 01");
TableCell cell2 = table.Rows[0].Cells[1];
Paragraph cell_paragraph2 = cell2.Blocks.AddParagraph();
editor.MoveToParagraphStart(cell_paragraph2);
editor.InsertText("cell content 02");
editor.MoveToTableEnd(table);
editor.InsertInline(bookmark.BookmarkRangeEnd);
RadFlowDocument newFlowDocument = new RadFlowDocument();
RadFlowDocumentEditor editor02 = new RadFlowDocumentEditor(newFlowDocument);
editor.InsertDocument(flowDocument);Workaround: Insert one bookmark before the table and another one after the table:
RadFlowDocument flowDocument = new RadFlowDocument();
RadFlowDocumentEditor editor = new RadFlowDocumentEditor(flowDocument);
//Bookmark bookmark = new Bookmark(flowDocument, "Name");
//editor.InsertInline(bookmark.BookmarkRangeStart);
editor.InsertBookmark("before");
Table table = editor.InsertTable(1, 2);
TableCell cell1 = table.Rows[0].Cells[0];
Paragraph cell_paragraph1 = cell1.Blocks.AddParagraph();
editor.MoveToParagraphStart(cell_paragraph1);
editor.InsertText("cell content 01");
TableCell cell2 = table.Rows[0].Cells[1];
Paragraph cell_paragraph2 = cell2.Blocks.AddParagraph();
editor.MoveToParagraphStart(cell_paragraph2);
editor.InsertText("cell content 02");
editor.MoveToTableEnd(table);
editor.InsertBookmark("after");
//editor.InsertInline(bookmark.BookmarkRangeEnd);
RadFlowDocument newFlowDocument = new RadFlowDocument();
RadFlowDocumentEditor editor02 = new RadFlowDocumentEditor(newFlowDocument);
editor.InsertDocument(flowDocument);
Use the code for inserting the code:
static void Main(string[] args)
{
Telerik.Windows.Documents.Flow.Model.RadFlowDocument templateDocument = GetDocument("Template.rtf");
Telerik.Windows.Documents.Flow.Model.RadFlowDocument contentDocument = GetDocument("Content.rtf");
InsertDocumentOptions options = new InsertDocumentOptions();
options.ConflictingStylesResolutionMode = ConflictingStylesResolutionMode.RenameSourceStyle;
options.InsertLastParagraphMarker = true;
RadFlowDocumentEditor editor = new RadFlowDocumentEditor(templateDocument);
editor.InsertDocument(contentDocument, options);
string mergedDocumentFilePath ="MergeDocumentsWithWordsProcessing.rtf";
File.Delete(mergedDocumentFilePath);
WriteDocToFile(templateDocument, mergedDocumentFilePath);
}
private static Telerik.Windows.Documents.Flow.Model.RadFlowDocument GetDocument(string rtfFilePath)
{
Telerik.Windows.Documents.Flow.Model.RadFlowDocument document = null;
var rtfImporter = new Telerik.Windows.Documents.Flow.FormatProviders.Rtf.RtfFormatProvider();
using (Stream stream = File.OpenRead(rtfFilePath))
{
document = rtfImporter.Import(stream);
}
return document;
}
private static void WriteDocToFile(Telerik.Windows.Documents.Flow.Model.RadFlowDocument doc, string filename)
{
var rtfExporter = new Telerik.Windows.Documents.Flow.FormatProviders.Rtf.RtfFormatProvider();
string rtfText = rtfExporter.Export(doc);
File.WriteAllText(filename, rtfText);
Process.Start(filename);
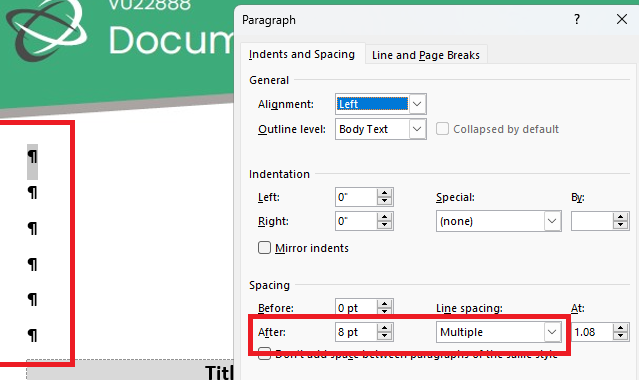
}Observed result: The After spacing is reset
Expected result: keep the style settings from the original documents.
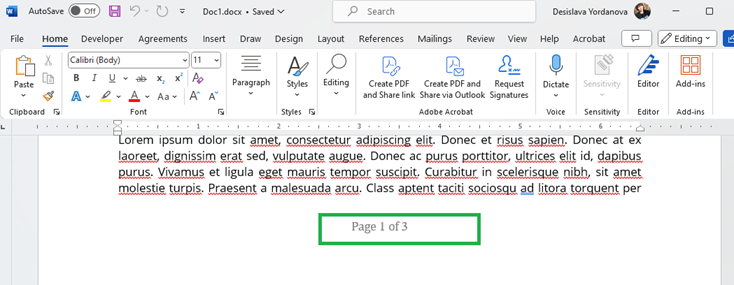
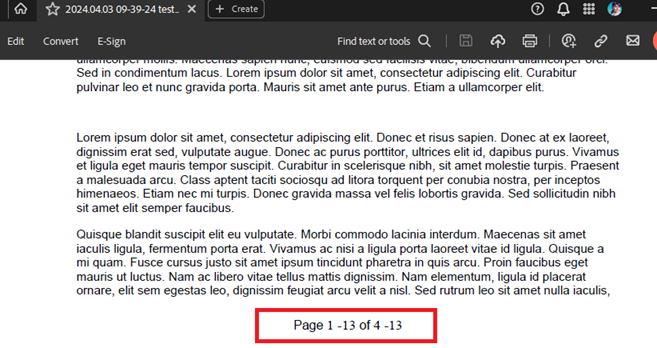
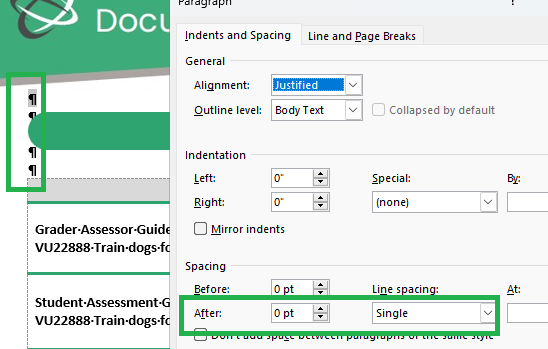
Converting some DocX files to PDF format with page numbering leads to incorrect formatting in the exported PDF:
Input DocX:
Output PDF:
Original DOCX document:
Exported DOCX document:
Workaround:
Telerik.Windows.Documents.Flow.Model.RadFlowDocument document;
Telerik.Windows.Documents.Flow.FormatProviders.Docx.DocxFormatProvider docXprovider = new Telerik.Windows.Documents.Flow.FormatProviders.Docx.DocxFormatProvider();
using (Stream input = File.OpenRead("PT1987 VU22888 Moodle Specification List [2024032716].docx"))
{
document = docXprovider.Import(input);
}
string normalStyleId = BuiltInStyleNames.NormalStyleId;
Style normalStyle = document.StyleRepository.AddBuiltInStyle(normalStyleId);
normalStyle.ParagraphProperties.SpacingAfter.LocalValue = 0;
normalStyle.ParagraphProperties.LineSpacing.LocalValue = 1;
Handle import of documents with self-referring styles.
As a workaround, you can go through the RTF document structure of a single file and utilize Regex to resolve the self-referring styles like this:
string rtf = File.ReadAllText("inputFile.rtf");
rtf = FixSelfReferringStyles(rtf);
Telerik.Windows.Documents.Flow.FormatProviders.Rtf.RtfFormatProvider provider = new Telerik.Windows.Documents.Flow.FormatProviders.Rtf.RtfFormatProvider();
var document = provider.Import(rtf);
...
private static string FixSelfReferringStyles(string rtf)
{
string regexString = @"{\\s([0-9]+)[^}]*\\slink([0-9]+)";
var matches = Regex.Matches(rtf, regexString);
foreach (Match match in matches)
{
if (match.Groups[1].Value == match.Groups[2].Value)
{
var oldValue = match.Groups[0].Value;
var newValue = oldValue.Replace(@" \slink" + match.Groups[1].Value, string.Empty);
rtf = rtf.Replace(oldValue, newValue);
}
}
return rtf;
}
Styles with names only different in spaces are treated as one.
Workaround:
var rtf = File.ReadAllText(fileName);
rtf = this.RenameStyleDifferentInOnlySpaces(rtf);
var document = provider.Import(rtf);
...
private string RenameStyleDifferentInOnlySpaces(string rtf)
{
HashSet<string> styles = new HashSet<string>();
string pattern = @"{\\(?:\*\\c)?s([0-9]+)[^}]*\n?[^}]*\\[^' ]* ?'?([^;]*)";
var matches = Regex.Matches(rtf, pattern);
foreach (Match match in matches)
{
string styleName = match.Groups[2].Value.Replace(" ", string.Empty);
if (styles.Contains(styleName))
{
styleName = this.ReplaceOldStyleName(ref rtf, styles, match).Replace(" ", string.Empty);
}
styles.Add(styleName);
}
return rtf;
}
private string ReplaceOldStyleName(ref string rtf, HashSet<string> styles, Match match)
{
string oldStyleName = match.Groups[2].Value;
StringBuilder styleNameBuilder = new StringBuilder(oldStyleName + "0");
while (styles.Contains(styleNameBuilder.ToString().Replace(" ", string.Empty)))
{
styleNameBuilder.Append("0");
}
string oldMatch = match.Groups[0].Value;
string newMatch = oldMatch.Replace(oldStyleName, styleNameBuilder.ToString());
rtf = rtf.Replace(oldMatch, newMatch);
return styleNameBuilder.ToString();
}
There are 27 types of border styles in the Open XML specification and they are implemented in RadFlowDocument. Only borders None and Single are supported when exporting to PDF, all others are treated as None and stripped.
Updates:
- The following feature request is created to handle the support of Thick, Dotted, Dashed, and DashSmallGap BorderStyles: Add support for Dotted, Dashed, and DashSmallGap borders.
Please subscribe to the tasks, so we can notify you when their status changes.
StackOverflowException when importing a document with style based on itself.
Use the following code to strip the faulty "based on" definition from the RTF:
RtfFormatProvider provider = new RtfFormatProvider();
var rtf = File.ReadAllText(ofd.FileName);
rtf = this.ReplaceSelfBasedOnStyle(rtf);
this.flowDocument = provider.Import(rtf);
...
private string ReplaceSelfBasedOnStyle(string rtf)
{
string pattern = @"{[\n]*\\s[0-9]+[^;]* \\\w* (Normal);}";
var matches = Regex.Matches(rtf, pattern);
foreach (Match match in matches)
{
string oldValue = match.Value;
string newValue = oldValue.Replace(@"\sbasedon0 ", string.Empty);
rtf = rtf.Replace(oldValue, newValue);
}
return rtf;
}
Import the following HTML content:
<ol type="a">
<li>
<div><p>WordsProcessing</p>
</div></li>
<li>
<div>
<p>SpreadProcessing</p>
</div>
</li>
<li>
<div>
<p>PdfProcessing</p>
</div>
</li>
</ol>The following error occurs: