Workaround: Change the current culture settings of the thread before exporting:
string cultureName = Thread.CurrentThread.CurrentCulture.Name;
CultureInfo cultureInfo= new CultureInfo(cultureName);
if (cultureInfo.NumberFormat.NumberDecimalSeparator != ".")
{
cultureInfo.NumberFormat.NumberDecimalSeparator = ".";
Thread.CurrentThread.CurrentCulture = cultureInfo;
}Borders are not correctly imported from HTML.
Workaround: Set borders in code:
var tables = document.EnumerateChildrenOfType<Table>();
var border = new Border(1, BorderStyle.Single, new ThemableColor(Colors.Black));
foreach (var table in tables)
{
table.Borders = new TableBorders(border);
foreach (var row in table.Rows)
{
foreach (var cell in row.Cells)
{
cell.Borders = new TableCellBorders(border);
}
}
}
There is a discrepancy between RadWordsProcessing and MS Word:
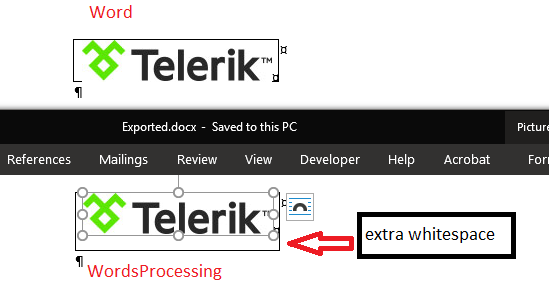
row.Height = new TableRowHeight(HeightType.Exact, image.Image.Height); There are 27 types of border styles in the Open XML specification and they are implemented in RadFlowDocument. Part of the borders are already supported (eg. None, Single, Dotted) when exporting to HTML, all others are treated as None and stripped.
The HTML format doesn't support all types of border styles OOXML format supports.
Exception when converting table with empty runs in the cells.
technologies or applications which do not display the current object. Currently it is omitted while importing the content with DocxFormatProvider
The hanging indent of the paragraph affects the rendering of content with tabs. However, the indent is not respected while generating the PDF, leading to disordered content.
Workaround: Insert a tab stop with the position set to the value for hanging indent:
foreach (var paragraph in this.flowDocument.EnumerateChildrenOfType<Paragraph>())
{
if (paragraph.Properties.HangingIndent.HasLocalValue)
{
Run run = paragraph.EnumerateChildrenOfType<Run>().Where(r => r.Text == "\t").FirstOrDefault();
if (run != null)
{
paragraph.TabStops = paragraph.TabStops.Insert(new Telerik.Windows.Documents.Flow.Model.Styles.TabStop(paragraph.Properties.HangingIndent.LocalValue.Value));
}
}
}