Nested Mail Merge cannot handle empty lists.
Workaround: Replace the empty list with null.
Merge field group in a single table cell causes it to replicate more times than expected.
Workaround: add a second column to the table and move the TableEnd/GroupEnd/EndGroup/RangeEnd merge field inside it.
Import/Export of specific documents sets style background color to black.
Workaround: do the following conversion of the document with the Document Processing libraries: originalRtf -> exportedDocx, exportedDocx -> finalRtf. After that processing, the finalRTF file will no longer reproduce the issue when exported.
PdfFormatProvider: Tab stop distance different from the default is not exported correctly.
Workaround: Use spaces instead.
Import the following HTML content:
<ol type="a">
<li>
<div><p>WordsProcessing</p>
</div></li>
<li>
<div>
<p>SpreadProcessing</p>
</div>
</li>
<li>
<div>
<p>PdfProcessing</p>
</div>
</li>
</ol>The following error occurs:
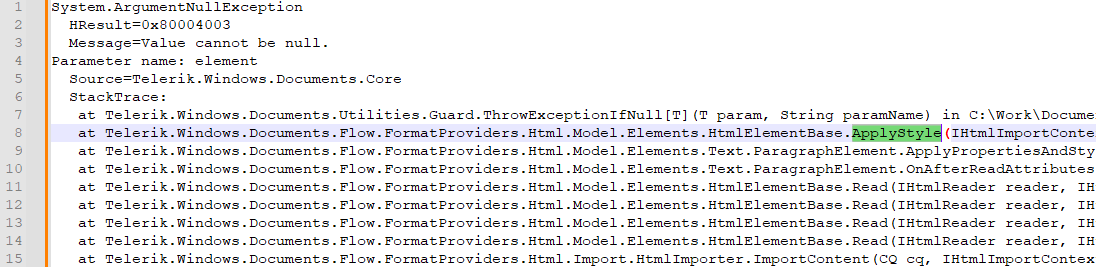
Converting some DocX files to PDF format with page numbering leads to incorrect formatting in the exported PDF:
Input DocX:
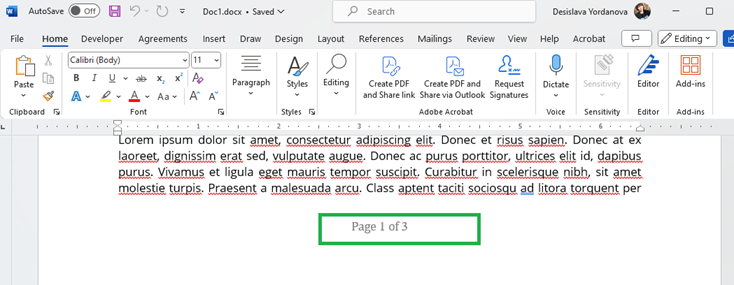
Output PDF:
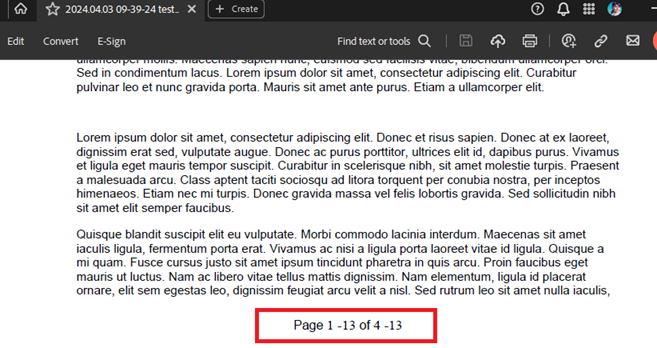
This is the code snippet that reproduces the error:
RadFlowDocument flowDocument = new RadFlowDocument();
RadFlowDocumentEditor editor = new RadFlowDocumentEditor(flowDocument);
Bookmark bookmark = new Bookmark(flowDocument, "Name");
editor.InsertInline(bookmark.BookmarkRangeStart);
Table table = editor.InsertTable(1, 2);
TableCell cell1 = table.Rows[0].Cells[0];
Paragraph cell_paragraph1 = cell1.Blocks.AddParagraph();
editor.MoveToParagraphStart(cell_paragraph1);
editor.InsertText("cell content 01");
TableCell cell2 = table.Rows[0].Cells[1];
Paragraph cell_paragraph2 = cell2.Blocks.AddParagraph();
editor.MoveToParagraphStart(cell_paragraph2);
editor.InsertText("cell content 02");
editor.MoveToTableEnd(table);
editor.InsertInline(bookmark.BookmarkRangeEnd);
RadFlowDocument newFlowDocument = new RadFlowDocument();
RadFlowDocumentEditor editor02 = new RadFlowDocumentEditor(newFlowDocument);
editor.InsertDocument(flowDocument);Workaround: Insert one bookmark before the table and another one after the table:
RadFlowDocument flowDocument = new RadFlowDocument();
RadFlowDocumentEditor editor = new RadFlowDocumentEditor(flowDocument);
//Bookmark bookmark = new Bookmark(flowDocument, "Name");
//editor.InsertInline(bookmark.BookmarkRangeStart);
editor.InsertBookmark("before");
Table table = editor.InsertTable(1, 2);
TableCell cell1 = table.Rows[0].Cells[0];
Paragraph cell_paragraph1 = cell1.Blocks.AddParagraph();
editor.MoveToParagraphStart(cell_paragraph1);
editor.InsertText("cell content 01");
TableCell cell2 = table.Rows[0].Cells[1];
Paragraph cell_paragraph2 = cell2.Blocks.AddParagraph();
editor.MoveToParagraphStart(cell_paragraph2);
editor.InsertText("cell content 02");
editor.MoveToTableEnd(table);
editor.InsertBookmark("after");
//editor.InsertInline(bookmark.BookmarkRangeEnd);
RadFlowDocument newFlowDocument = new RadFlowDocument();
RadFlowDocumentEditor editor02 = new RadFlowDocumentEditor(newFlowDocument);
editor.InsertDocument(flowDocument);
In a WPF project targeting .NET 6, the following code snippet results in an error:
public MainWindow()
{
InitializeComponent();
Telerik.Windows.Documents.Flow.FormatProviders.Html.HtmlFormatProvider provider = new Telerik.Windows.Documents.Flow.FormatProviders.Html.HtmlFormatProvider();
RadFlowDocument document = provider.Import("<html><body><h1>My First Heading</h1><p>My first paragraph.</p></body></html>");
}System.IO.FileNotFoundException: 'Could not load file or assembly 'System.Text.Encoding.CodePages, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a'. The system cannot find the file specified.'
Workaround: edit the .csproj file and include the required package reference:
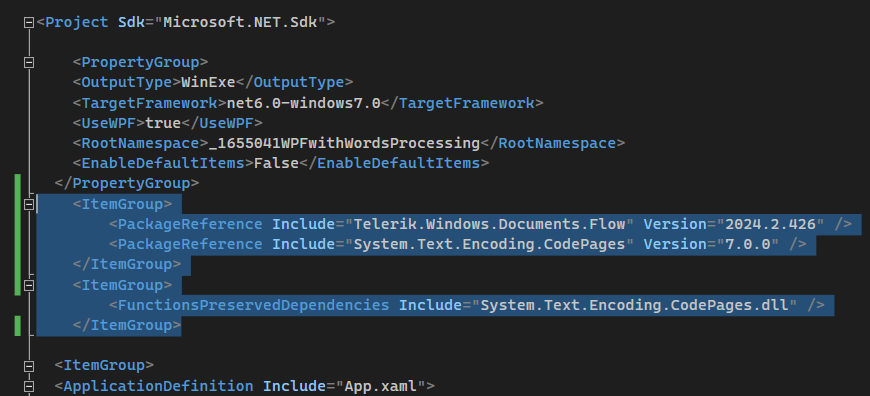
<ItemGroup>
<PackageReference Include="Telerik.Windows.Documents.Flow" Version="2024.2.426" />
<PackageReference Include="System.Text.Encoding.CodePages" Version="7.0.0" />
</ItemGroup>
<ItemGroup>
<FunctionsPreservedDependencies Include="System.Text.Encoding.CodePages.dll" />
</ItemGroup>