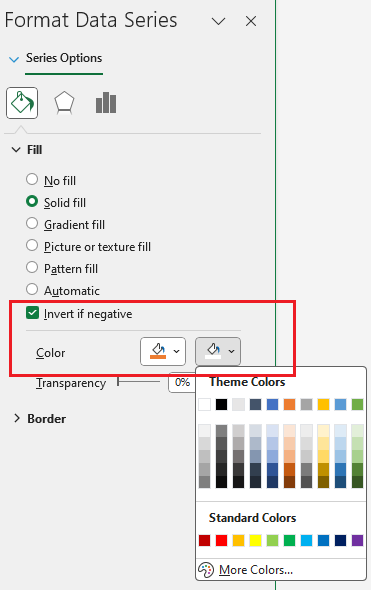
Add support for "Invert if negative" property of chart data series fill.
Hello! I'd like to request that the WorksheetPrintOptions library be able to specify what duplex to print. This is regarding:
namespace Telerik.Windows.Documents.Spreadsheet.Model;
In Excel there are currently 3 options (for my printer):
Print One Sided
Print on Both Sides (pages flip on Long Edge)
Print on Both Sides (pages flip on Short Edge)
Currently at my company, in order to save paper the default for everyone's printers is Print on Both Sides (Long Edge). (Our printer, btw, is a Canon iR-ADV C3826 UFR II).
On a report I have created in Excel with Telerik, it's 3 pages but it's meant to clip onto a clipboard so it can't be double sided. So I would like the option to do this:
worksheet.WorksheetPageSetup.PrintOptions.Duplex = PrintOptionsDuplex.OneSided;
something like that. However you want to implement it is fine. Duplex may be the wrong word here. Maybe just .OneSided = true; or .BothSidesLong = true; or something.
Anyhow, I think that would be handy for my particular instance, and I think printing both sided for most people might save a lot of paper too so it might benefit other situations as well.
For now, I will instruct my clients they have to just manually switch to One Sided each time the print this report.
Thanks!
For the Telerik Spreadsheet control, XlsxFormatProvider.Export() API is used for saving the .xlsx file manually without the UI command(Save As dialog) invocation. This API is currently returning a byte stream.
The requirement is that the API should also intimate the user whether the export is successful or not by returning a boolean value.
Note: I think we can implement this requirement at the base level which is for the BinaryFormatProviderBase class or atleast at the FormatProviderBase class.
If I simply import the xls file with the XlsFormatProvider that RadSpreadProcessing offers and then export it either to xls or xlsx format, the following message pops up when opening the document in MS Excel:
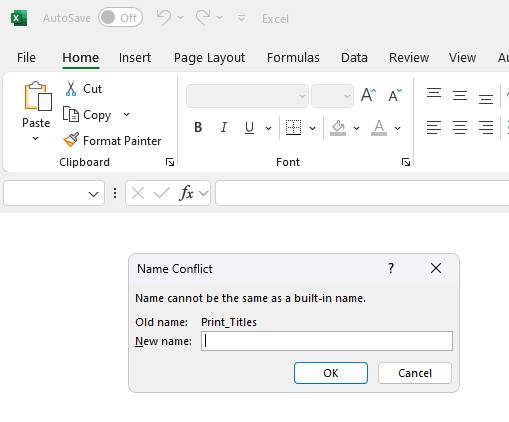
The exported XLS or XLSX file with RadSpreadProcessing contains an additional <definedName>:
<?xml version="1.0" encoding="utf-8"?>
<workbook xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main">
<sheets>
<sheet sheetId="1" name="Sheet1" state="visible" r:id="rId1" />
</sheets>
<definedNames>
<definedName name="Print_Titles" localSheetId="0" hidden="false">Sheet1!$A$1:$IV$3</definedName>
<definedName name="_xlnm.Print_Area" localSheetId="0" hidden="false">Sheet1!$A:$G</definedName>
<definedName name="_xlnm.Print_Titles" localSheetId="0" hidden="false">Sheet1!$1:$3</definedName>
</definedNames>
</workbook>
Use the following code to create the document:
Workbook workbook = new Workbook();
Worksheet graphWorksheet = workbook.Worksheets.Add();
FloatingChartShape chartShape = new FloatingChartShape(graphWorksheet,
new CellIndex(0, 0),
new CellRange(0, 0, 0, 0), ChartType.Column)
{
Width = 500,
Height = 500,
};
graphWorksheet.Charts.Add(chartShape);
DocumentChart chart = new DocumentChart();
BarSeriesGroup barSeriesGroup = new BarSeriesGroup();
barSeriesGroup.BarDirection = BarDirection.Column;
StringChartData barCategoryData = new StringChartData(new List<string>() { "1.1", "1.2", "1.3", "1.4", "2.1", "3.1", "4.1", "4.2", "4.3" });
IEnumerable<double> percentEvidentList = new List<double>() { Math.Round((double)0.9914 * 100, 4) , Math.Round((double)0.7719 * 100, 4), Math.Round((double)1 * 100, 4) };
NumericChartData barValues = new NumericChartData(percentEvidentList);
BarSeries series = new BarSeries();
series.Categories = barCategoryData;
series.Values = barValues;
ThemableColor themableColor = ThemableColor.FromArgb(255, 125, 0, 125);
series.Fill = new SolidFill(themableColor);
series.Title = new TextTitle("FY 20");
barSeriesGroup.Series.Add(series);
chart.SeriesGroups.Add(barSeriesGroup);
ValueAxis valueAxis = new ValueAxis();
valueAxis.Min = 0;
valueAxis.Max = 100;
valueAxis.NumberFormat = "0%";
CategoryAxis categoryAxis = new CategoryAxis();
chart.PrimaryAxes = new AxisGroup(categoryAxis, valueAxis);
chart.Legend = new Legend();
chart.Legend.Position = LegendPosition.Left;
chartShape.Chart = chart;
valueAxis.NumberFormat = "0%";
string outputFilePath = "SampleFile.xlsx";
File.Delete(outputFilePath);
IWorkbookFormatProvider formatProvider = new Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.XlsxFormatProvider();
using (Stream output = new FileStream(outputFilePath, FileMode.Create))
{
formatProvider.Export(workbook, output, TimeSpan.FromSeconds(10));
}
Process.Start(new ProcessStartInfo() { FileName = outputFilePath, UseShellExecute = true });The COUNTA function counts cells containing any type of information, including error values and empty text ("")
https://support.microsoft.com/en-us/office/counta-function-7dc98875-d5c1-46f1-9a82-53f3219e2509
Here are the steps:
1. Copy some basic content from Excel (two text cells)
2. Paste the content to the Telerik Blazor Spreadsheet component and save the XLSX file
3. Try importing this file with RadSpreadProcessing