Recently Updated
Completed
Last Updated:
24 Jun 2026 10:31
by ADMIN
Release Scheduled For = 2026.2.624 (2026 Q2)
Created by:
Rey
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
When merging documents using the RadFixedDocument`s Merge() method the fonts are not successfully merged which leads to missing characters in the produced document.
Workaround: replace the font with a full font (not a subset) before exporting to a PDF file:
Workaround: replace the font with a full font (not a subset) before exporting to a PDF file:
byte[] data = File.ReadAllBytes("verdana.ttf");
FontFamily verdanaRegularFontFamily = new FontFamily("Verdana");
FontsRepository.RegisterFont(verdanaRegularFontFamily, FontStyles.Normal, FontWeights.Normal, data);
FontsRepository.TryCreateFont(verdanaRegularFontFamily, out FontBase verdanaRegularFont);
foreach (RadFixedPage page in mergedDocument.Pages)
{
foreach (TextFragment textFragment in page.Content.Where(c => c is TextFragment).Cast<TextFragment>())
{
textFragment.Font = verdanaRegularFont;
}
}
Completed
Last Updated:
24 Jun 2026 10:31
by ADMIN
Release Scheduled For = 2026.2.624 (2026 Q2)
Created by:
Devron
Comments:
2
Category:
PdfProcessing
Type:
Bug Report
This exception was originally thrown at this call stack:
System.ThrowHelper.ThrowArgumentOutOfRange_IndexMustBeLessException()
System.Collections.Generic.List<T>.this[int].get(int)
Telerik.Windows.Documents.Core.PostScript.Data.PostScriptArray.GetElementAs<T>(int)
Telerik.Windows.Documents.Core.Fonts.Type1.Type1Format.Dictionaries.Type1PostScriptObject.GetGlyphName(ushort)
Telerik.Windows.Documents.Core.Fonts.Type1.Type1Format.Type1FontSource.GetGlyphName(ushort)
Telerik.Windows.Documents.Core.Fonts.Type1.Type1Format.Type1FontSource.GetAdvancedWidthOverride(int)
Telerik.Windows.Documents.Core.Fonts.FontSource.GetAdvancedWidth(int)
Telerik.Windows.Documents.Fixed.Model.Fonts.StandardFont.GetActualWidth(Telerik.Windows.Documents.Fixed.Model.Data.CharCode)
Telerik.Windows.Documents.Fixed.Model.Fonts.SimpleFont.GetWidthOverride(Telerik.Windows.Documents.Fixed.Model.Data.CharCode)
Telerik.Windows.Documents.Fixed.Model.Fonts.FontBase.GetWidth(Telerik.Windows.Documents.Fixed.Model.Data.CharCode)
System.ThrowHelper.ThrowArgumentOutOfRange_IndexMustBeLessException()
System.Collections.Generic.List<T>.this[int].get(int)
Telerik.Windows.Documents.Core.PostScript.Data.PostScriptArray.GetElementAs<T>(int)
Telerik.Windows.Documents.Core.Fonts.Type1.Type1Format.Dictionaries.Type1PostScriptObject.GetGlyphName(ushort)
Telerik.Windows.Documents.Core.Fonts.Type1.Type1Format.Type1FontSource.GetGlyphName(ushort)
Telerik.Windows.Documents.Core.Fonts.Type1.Type1Format.Type1FontSource.GetAdvancedWidthOverride(int)
Telerik.Windows.Documents.Core.Fonts.FontSource.GetAdvancedWidth(int)
Telerik.Windows.Documents.Fixed.Model.Fonts.StandardFont.GetActualWidth(Telerik.Windows.Documents.Fixed.Model.Data.CharCode)
Telerik.Windows.Documents.Fixed.Model.Fonts.SimpleFont.GetWidthOverride(Telerik.Windows.Documents.Fixed.Model.Data.CharCode)
Telerik.Windows.Documents.Fixed.Model.Fonts.FontBase.GetWidth(Telerik.Windows.Documents.Fixed.Model.Data.CharCode)
Completed
Last Updated:
24 Jun 2026 10:31
by ADMIN
Release Scheduled For = 2026.2.624 (2026 Q2)
Created by:
Dimitar
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
Exception when merging file that contains notdef characters with PdfStreamWriter
Completed
Last Updated:
24 Jun 2026 10:31
by ADMIN
Release Scheduled For = 2026.2.624 (2026 Q2)
Created by:
Nils
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
Add support for XRechnung compliance.
Completed
Last Updated:
24 Jun 2026 10:31
by ADMIN
Release Scheduled For = 2026.2.624 (2026 Q2)
Created by:
Giovanni Rojas
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
Add support for Encryption Algorithm 7.
Completed
Last Updated:
24 Jun 2026 10:31
by ADMIN
Release Scheduled For = 2026.2.624 (2026 Q2)
Created by:
Stefan
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
Here is a sample structure of the signature:
/Type /Sig /SubFilter /adbe.x509.rsa_sha1 /Filter /Adobe.PPKMS
Unplanned
Last Updated:
23 Jun 2026 07:49
by Kristijan
Created by:
Kristijan
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
Error 141 TYPECHECK on Lexmark printer when printing DPL-generated PDF file.
Completed
Last Updated:
19 May 2026 20:44
by ADMIN
Release 2026.3.519 (2026 Q2)
ADMIN
Created by:
Martin
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
Grid PDF Export fails on Blazor WASM with CryptographicException: MD5.
Root Cause:
PdfExportContext.CreateDocumentId() calls System.Security.Cryptography.MD5.Create(). MD5 is not available in the .NET WASM runtime by default and throws CryptographicException.
Root Cause:
PdfExportContext.CreateDocumentId() calls System.Security.Cryptography.MD5.Create(). MD5 is not available in the .NET WASM runtime by default and throws CryptographicException.
Completed
Last Updated:
19 May 2026 20:44
by ADMIN
Release 2026.3.519 (2026 Q2)
Created by:
Sandy
Comments:
8
Category:
PdfProcessing
Type:
Bug Report
Corrupted document when exporting "Courier New" subset.
Workaround - fully embed the font:
var pdfFormatProvider = new PdfFormatProvider();
pdfFormatProvider.ExportSettings.FontEmbeddingType = FontEmbeddingType.Full;NOTE: There are reports for other fonts' subset, e.g. "ZapfDingbats" font.
Completed
Last Updated:
19 May 2026 20:44
by ADMIN
Release 2026.3.519 (2026 Q2)
Created by:
Greg
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
NetStandard: Missing content due to empty glyph outlines in embedded TrueType font subsets.
Workaround 1
Fully embed the fonts in the result PDF document:
PdfFormatProvider pdfFormatProvider = new PdfFormatProvider();
pdfFormatProvider.ExportSettings.FontEmbeddingType = FontEmbeddingType.Full;Workaround 2
Switch to a .NET Framework project environment and use the .NET Framework PdfProcessing packages.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
Created by:
Vitalii
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
NullReferenceException is thrown when exporting pages containing images with missing optional ColorSpace.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
Created by:
Janson
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
When signing more than one signature field, the previous signatures are invalidated.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
Created by:
Adrian
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
NullReferenceException is thrown then exporting a document with a Type 3 font with missing/invalid Unicode mapping.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
Created by:
David
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
PdfStreamWriter stream-copy page splitting performance is much slower than expected in some cases. When working with larger PDF files, the processing time can increase a lot and cause noticeable delays.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
Created by:
Simon
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
XMP metadata is unescaped during import/export.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
Created by:
Sachin
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
When inserting a specific Jpeg image with an ICC profile there is a problem when opening the file in Adobe:
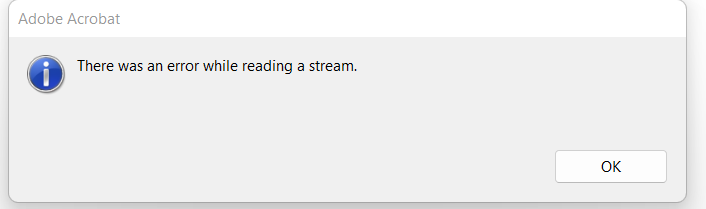
On the other hand, the PDF is successfully opened by browsers and most PDF viewers.
On the other hand, the PDF is successfully opened by browsers and most PDF viewers.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
Created by:
Mattia
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
Duplicated page content due to an incorrect caching mechanism.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
Created by:
Prashant
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
This will allow the import of Tensor-product patch mesh gradients. Currently, importing documents that contain ShadingType 7 results in NotSupportedShadingTypeException.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
Created by:
edwin tan
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
ADMIN
Created by:
Tanya
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
This type of shading is not supported in the current version and a NotSupportedException is thrown when importing documents containing it.
The exception can be suppressed using the Exception Handling mechanism of PdfProcessing.
The exception can be suppressed using the Exception Handling mechanism of PdfProcessing.