Completed
Last Updated:
15 Aug 2025 13:49
by ADMIN
Release 2025.3.806 (2025 Q3)
Created by:
Vitalii
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
This error happens when importing a document.
Completed
Last Updated:
15 Aug 2025 13:49
by ADMIN
Release 2025.3.806 (2025 Q3)
ADMIN
Created by:
Deyan
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
The standard fonts listed at http://docs.telerik.com/devtools/wpf/controls/radpdfprocessing/concepts/fonts#standard-fonts cannot be embedded in a document. Using one of them prevents the document from complying with PDF/A standard.
Completed
Last Updated:
26 Jan 2026 14:27
by ADMIN
Release 2025.4.1216 (2025 Q4)
ADMIN
Created by:
Tanya
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
Some PDF files have an additional content added before the file header (before %PDF-1.4 for example). This additional content makes all byte offsets in the document invalid, which causes the format provider to throw an exception. At this point, to import a similar document it should be pre-processed so the content before the version header is removed before importing it.
Completed
Last Updated:
27 Mar 2020 10:46
by ADMIN
Release R2 2020
ADMIN
Created by:
Tanya
Comments:
4
Category:
PdfProcessing
Type:
Bug Report
When merging, only the widgets are copied but not their fields. This can lead to ArgumentNullException when exporting the document. Implement copying the fields and consider cases which include collision of names of the fields. Workaround: Repair the generated document using the following code:In case of Name collision, you can use the attached project or the attached project to the following feedback item to rename the duplicate fields: Provide a way to rename FormFields.foreach(Widget widgetinthis.pdfDocument.Annotations.Where(annot => annot.Type == AnnotationType.Widget)){if(!this.pdfDocument.AcroForm.FormFields.Contains(widget.Field.Name)){this.pdfDocument.AcroForm.FormFields.Add(widget.Field);}}
Unplanned
Last Updated:
29 Feb 2024 13:34
by ADMIN
Created by:
Josh
Comments:
4
Category:
PdfProcessing
Type:
Feature Request
A free text annotation displays text directly on the page. Unlike an ordinary text annotation, a free text annotation has no open or closed state; instead of being displayed in a pop-up window, the text is always visible.
Completed
Last Updated:
10 Feb 2023 07:14
by ADMIN
Release LIB 2023.1.220 (20 Feb 2023)
Created by:
Jordi
Comments:
5
Category:
PdfProcessing
Type:
Bug Report
After signing a document using the PdfProcessing library and the document is loaded in Adobe Acrobat an error is shown when the signature widget is clicked:
Error during signature verification.
Adobe Acrobat error.
Expected a dict object.
Error during signature verification.
Adobe Acrobat error.
Expected a dict object.
Completed
Last Updated:
15 Aug 2025 13:49
by ADMIN
Release 2025.3.806 (2025 Q3)
Created by:
Kris
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
PDF/UA (PDF/Universal Accessibility) is the informal name for ISO 14289, the International Standard for accessible PDF technology.
Completed
Last Updated:
27 Feb 2023 14:53
by ADMIN
Release R1 2023 SP1
Created by:
Nafly
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
The current implementation relies on valid cross-reference offsets in the PDF documents so that PDF objects are easily found and parsed. However, a mechanism for importing documents with invalid offsets for the objects inside the stream can be implemented.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
ADMIN
Created by:
Tanya
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
This type of shading is not supported in the current version and a NotSupportedException is thrown when importing documents containing it.
The exception can be suppressed using the Exception Handling mechanism of PdfProcessing.
The exception can be suppressed using the Exception Handling mechanism of PdfProcessing.
Completed
Last Updated:
10 Oct 2025 06:11
by ADMIN
Release 2025.3.1007 (2025 Q3)
Created by:
Vitalii
Comments:
2
Category:
PdfProcessing
Type:
Bug Report
Part of the stack trace:
System.OutOfMemoryException: Insufficient memory to continue the execution of the program.
at System.Text.StringBuilder.ExpandByABlock(Int32 minBlockCharCount)
at System.Text.StringBuilder.AppendWithExpansion(Char value)
at System.Text.StringBuilder.Append(Char value)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Utilities.CrossReferenceCollectionReader.GetAllText(Reader reader, Int64 minOffset, Int64 maxOffset)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Utilities.CrossReferenceCollectionReader.FindAllObjectOffsets(Reader reader, Dictionary`2 tokenToOffsets, Int64 minOffset, Int64 maxOffset)Solution - use the ExpandableMemoryStream for the import instead.
Completed
Last Updated:
15 Aug 2025 13:49
by ADMIN
Release 2025.3.806 (2025 Q3)
Created by:
Vitalii
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
Error message:
System.InvalidCastException: 'Unable to cast object of type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfArray' to type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Functions.FunctionObject'.'
Completed
Last Updated:
26 Jan 2026 14:32
by ADMIN
Release 2025.2.520 (2025 Q2)
Created by:
Vitalii
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
Error message:
System.InvalidCastException: 'Unable to cast object of type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Forms.FormFieldsTree' to type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfArray'.'
Completed
Last Updated:
26 Jan 2026 14:27
by ADMIN
Release 2025.4.1216 (2025 Q4)
Created by:
Vitalii
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
When importing a large document (e.g. 2.3GB) , the library fails to parse int value that exceeds the limit which leads to endless importing:
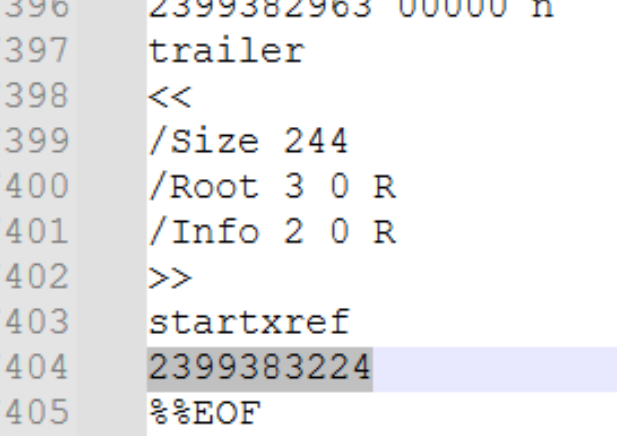
Completed
Last Updated:
13 Feb 2026 09:39
by ADMIN
Release 2026.1.210 (2026 Q1)
Created by:
Vitalii
Comments:
0
Category:
PdfProcessing
Type:
Bug Report
SkiaImageFormatProvider: Blacked out images due to incorrectly resolved clipping.
Completed
Last Updated:
17 Sep 2019 07:30
by ADMIN
Release R3 2019
ADMIN
Created by:
Deyan
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
Add support for ToUnicode CMap stream. A side effect of not supporting it is the following: exporting PDF document which, for example, contains German umlauts, to plain text, leads to wrong characters in the resulting text. As possible workaround, the PdfFormatProvider instance of RadPdfViewer can be used to import the document. For example:FormatProviderSettings settings =newFormatProviderSettings(ReadingMode.OnDemand);PdfFormatProvider pdfViewerFormatProvider =newPdfFormatProvider(stream, settings);RadFixedDocument document = pdfViewerFormatProvider.Import();TextFormatProvider textFormatProvider =newTextFormatProvider();String text = textFormatProvider.Export(document);
Completed
Last Updated:
14 Mar 2024 09:00
by ADMIN
Release 2024.1.305 (2024 Q1)
ADMIN
Created by:
Deyan
Comments:
2
Category:
PdfProcessing
Type:
Bug Report
For example exporting the text "\uD83D\uDE0A" with "Segoe UI Symbol" font family should export a single smiling face. Instead the characters are skipped during the export as PdfProcessing is trying to export them as separate char values ("\uD83D" and "\uDE0A") and the font does not contain glyphs corresponding to these char codes.
Unplanned
Last Updated:
25 Apr 2018 07:52
by ADMIN
ADMIN
Created by:
Peshito
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
Text fields should support rich text strings allowing the user to use rich text elements and attributes.
Completed
Last Updated:
13 Nov 2024 08:51
by ADMIN
Release 2024.4.1106 (Q4 2024)
Created by:
Craig
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
Sometimes customers need to create documents using the CMYK colors to meet specific requirements for printing. Expose such functionality in PdfProcessing.
Completed
Last Updated:
24 Feb 2023 13:41
by ADMIN
Release R1 2023 SP1
Created by:
Manel
Comments:
7
Category:
PdfProcessing
Type:
Bug Report
The current implementation relies on valid cross-reference offsets in the PDF documents so that PDF objects are easily found and parsed. However, we may implement a mechanism for importing documents with invalid offsets for the objects inside the table.
Unplanned
Last Updated:
11 Jun 2020 09:06
by ADMIN
Created by:
Eugene
Comments:
0
Category:
PdfProcessing
Type:
Feature Request
More information is available in the Pdf Reference 1.7. Page 442 lists all predefined CMaps that should be imported and exported as PdfName objects. At this point, trying to import a document with such encoding, a NotSupportedException is thrown with message Encoding type is not supported.