PDF content:

Exported text content:

When you register a font in an ASP.Core project and in a static constructor, the generated PDF document will have this font only the first time you load the web page. Refreshing the page will generate the PDF document but the fonts will be lost.
Note: This worked in the previous version 2025.2.701.
When importing a document with an invalid creation or modification date, an exception is thrown:
- FormatException: 'The input string '' was not in a correct format.'
- ArgumentOutOfRangeException: 'Year, Month, and Day parameters describe an unrepresentable DateTime.'
The issue is not reproducible in Q1 2025 (2025.1.205).
In Q2 2025 we introduced the MarkedContent in a RadFixedDocument.
Currently the DocumentInfo property is for export purposes only and meta information about documents is stripped when importing.
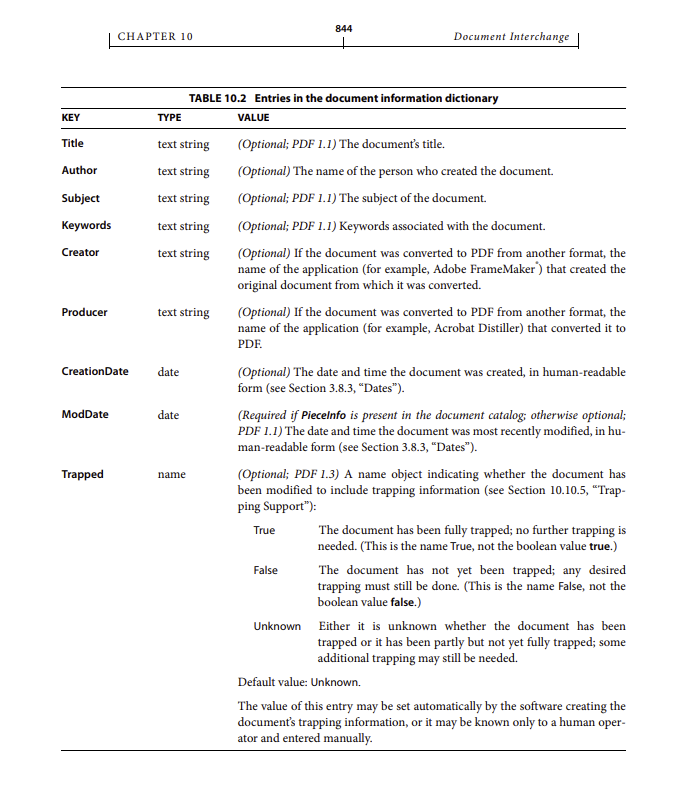
According to the PDF specification (ISO 32000), the document info dictionary (often called "metadata" or "Info" dictionary) can include the following standard fields:
• Title: The document’s title.
• Author: The name of the person who created the document.
• Subject: The subject of the document.
• Keywords: Keywords associated with the document.
• Creator: The application that created the original document.
• Producer: The application that converted the document to PDF.
• CreationDate: The date and time the document was created.
• ModDate: The date and time the document was last modified.
• Trapped: Indicates whether the document has been trapped (a printing term).
These fields are stored in the PDF’s Info dictionary and are used by PDF viewers for display, search, and indexing.
It would be great if the SkiaImageExportSettings offer a DocumentUnhandledException event allowing the developer to handle specific errors when exporting to image formats.
This would be an essential improvement in the existing Exception handling mechanism and would enable exporting PDF documents to images even though some parts of the image may not be completely supported: https://docs.telerik.com/devtools/document-processing/libraries/radpdfprocessing/features/handling-document-exceptions
When exporting a PDF page to an image with the SkiaImageFormatProvider the following error occurs:
System.IndexOutOfRangeException: 'Index was outside the bounds of the array.'
Such a document can be considered invalid. However, it would be good to provide functionality to handle it.
Update: After reviewing the case, we concluded that the issue is caused by the document being linearized. Therefore, this item is being marked as a duplicate. Please follow the related public item to receive notifications about future status updates.
Purpose: Long-term archiving of electronic documents with full semantic structure.
- "A" for Archiving
Level "1a" ensures:
Tagged PDF (with proper logical structure and reading order)
Unicode text for proper text extraction and searchability
Embedded fonts (for consistent rendering)
Restrictions:
No audio/video
No encryption
No JavaScript
No external content (everything must be self-contained)
Based on: PDF 1.4 (Acrobat 5)