Declined: This task is obsolete following the introduction of the current Licensing Mechanism.
------------------------------------------------------------------
Currently EULA requires Telerik assemblies to be protected against unauthorized redistribution, by following specific guidelines for the different types of technology:
- for WPF: https://docs.telerik.com/devtools/wpf/installation-and-deployment/deploying-telerik-ui/protecting-telerik-assembly - for ASP.NET AJAX: https://docs.telerik.com/devtools/aspnet-ajax/deployment/protecting-the-telerik-asp.net-ajax-assembly - for WinForms: https://docs.telerik.com/devtools/winforms/installation-deployment-and-distribution/redistributing-telerik-ui-for-winforms When the guidelines for WinForms or AJAX are followed (namely the call to ValidatePassPhrase() is uncommented in AssemblyProtection.IsValid() method, the following license message is added to the generated documents: "This document was generated by a copy of Telerik Document Processing licensed for use only by '<MyApp>'."Workaround: Set the application name as resource in the Application.Current, using the following code:
newSystem.Windows.Application();System.Windows.Application.Current.Resources.Add("Telerik.Windows.Controls.Key","MyApp");where 'MyApp' should be replaced with the actual application name. References to PresentationFramework and WindowsBase .NET Framework assemblies should be added in order for this approach to work.
We use the PDF viewer in an WPF project and see sometimes faulty pdfs in the telerik viewer. If I open the pdf file in acrobat it lloks fine. Do you know this problem ?
Attached you find the original file and a screenshot from PDF viewer. Other files are shown correct in the telerik viewer.
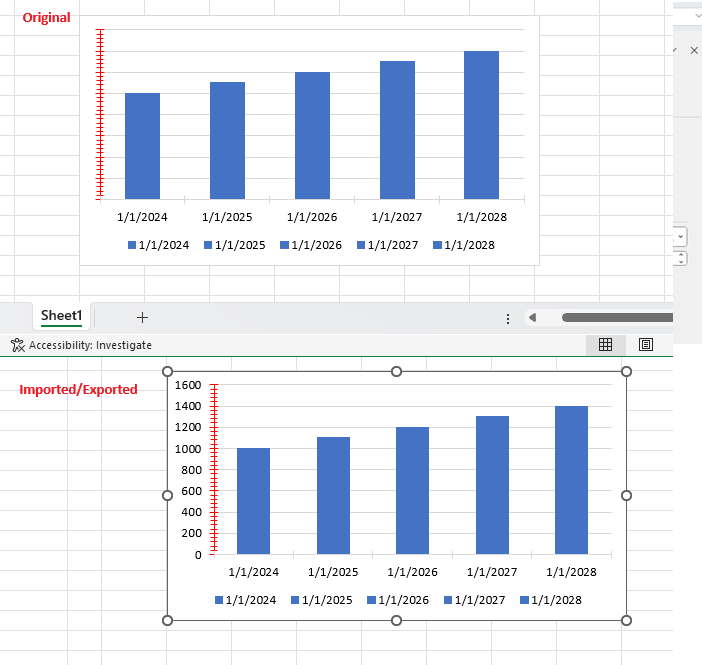
Workaround: this is the missing part after the export:

The issue is reproducible with PDF form fields and setting Polish characters to the text fields: e.g. "ęóąśłżźćń"
Edit mode in RadPdfViewer:
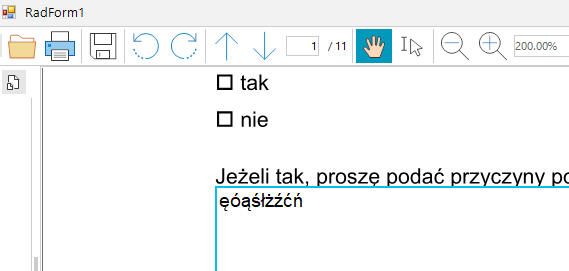
Exit edit mode:

Here is a sample code snippet for reproducing the case without UI:
PdfFormatProvider provider = new PdfFormatProvider();
RadFixedDocument document = provider.Import(File.ReadAllBytes("file.pdf"), TimeSpan.FromSeconds(10));
foreach (RadFixedPage page in document.Pages)
{
foreach (Annotation annotation in page.Annotations)
{
if (annotation.Type == AnnotationType.Widget)
{
Widget widget = (Widget)annotation;
var field = widget.Field as TextBoxField;
if (field != null)
{
field.Value = "ęóąśłżźćń.";
}
}
}
}
string outputFilePath = "result.pdf";
File.Delete(outputFilePath);
File.WriteAllBytes(outputFilePath, provider.Export(document, TimeSpan.FromSeconds(10)));
Process.Start(new ProcessStartInfo() { FileName = outputFilePath, UseShellExecute = true });
Generate a sample document with RadPdfProcessing and export it with AES-256 encryption. Try to open it on an iPhone with the default Pdf Viewer of iOS. The document is empty. However, the mobile version of Adobe for iOS opens the document successfully.
Read the documentation for CancelationTokenSource.CancelAfter:
this method will throw an ArgumentOutOfRangeException when: delay.TotalMilliseconds is less than -1 or greater than Int32.MaxValue (or UInt32.MaxValue - 1 on some versions of .NET). Note that this upper bound is more restrictive than TimeSpan.MaxValue.
----------------------------------------------------
your code in CancelationTokenSourceFactory.CreateTokenSource does this check:
if (timeSpan.HasValue && timeSpan.Value != TimeSpan.MaxValue)this check for TimeSpan.MaxValue seems totally pointless here, if timeSpan is anything between ~2147483647 and 922337203685476 milliseconds long this will still just throw a ArgumentOutOfRangeException.
I suspect that this check was intended as a way to prevent creating a cancellation timer that never triggers in the CancellationTokenSource, which should look like this:
if (timeSpan.HasValue && timeSpan != Timeout.InfiniteTimeSpan) //Timeout.InfiniteTimeSpan is -1 millisecondsWhen creating a data bar conditional formatting with middle axis, a plain data bar with left axis is created instead. Using the following code:
var dataBarValueContext = new DataBarValueContext
{
MaximumValue = new NumericValue(1),
MinimumValue = new NumericValue(-1)
};
// Create the rule and set the desired formatting
var rule = new DataBarRule(dataBarValueContext)
{
UseGradientFill = false,
Direction = DataBarDirection.Context,
FillColor = ThemableColor.FromColor(Colors.Green),
NegativeFillColor = ThemableColor.FromColor(Colors.Red),
ShowBarsOnly = true,
AxisPosition = DataBarAxisPosition.Automatic
};
var conditionalFormat = new ConditionalFormatting(rule);
worksheet.Cells[0, 0, 1, 0].AddConditionalFormatting(conditionalFormat);
worksheet.Cells[0, 0].SetValue(0.5);
worksheet.Cells[1, 0].SetValue(-0.5);
The expected value is this:
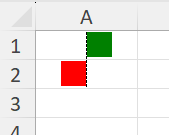
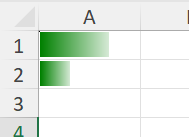
The result value is instead:
In the 2025 version of the Documents packages, "TimeSpan? timeout" were added to a number of interfaces, with the old versions obsoleted, for example: IWorkbookFormatProvider.Import & IWorkbookFormatProvider.Export.
This is a very strange choice, because this limits the flexibility of the interfaces for no reason at all. By only providing the TimeSpan parameter and not a CancellationToken is currently impossible to cancel the operation because e.g. an API request was canceled.
Internally these methods are implemented by first creating a cancellation token using
using CancellationTokenSource cancellationTokenSource = CancelationTokenSourceFactory.CreateTokenSource(timeout);the token from this CancellationTokenSource is then passed to a protected method. Because this internal method uses a CancellationToken anyway, there is practically 0 development cost to exposing this in the interface, which makes the choice not to do so even more confusing.
The interfaces should expose methods that take a CancellationToken instead of a TimeSpan. This would allow for the same functionality as the TimeSpan parameter, by simply passing a cancellation token with a CancelAfter set with a TimeSpan, and an extension method could be provided for the interface which does exactly that, so users can still call these methods with a TimeSpan parameter if they wish to do so for convenience.
Please, in the next version, make these interfaces methods like this:
Workbook Import(Stream input, CancellationToken cancellationToken = default);
void Export(Workbook workbook, Stream output, CancellationToken cancellationToken = default);and, for convenience, add extension methods for these like this:
public static class WorkbookFormatProviderExtensions
{
public static Workbook Import(this IWorkbookFormatProvider workbookFormatProvider, Stream input, TimeSpan? timeout)
{
using CancellationTokenSource cancellationTokenSource = CancelationTokenSourceFactory.CreateTokenSource(timeout);
return workbookFormatProvider.Import(input, cancellationTokenSource.Token);
}
}Affected interfaces I've run into so far:
- Telerik.Windows.Documents.Spreadsheet.FormatProviders.IWorkbookFormatProvider
- Telerik.Windows.Documents.Common.FormatProviders.IFormatProvider<T>
There may be more with this same pattern, I haven't checked.
PdfFormatProvider provider = new PdfFormatProvider();RadFixedDocument fixedDocument = provider.Import(document.ByteArray);
System.NullReferenceException: Object reference not set to an instance of an object.
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.RadFixedDocumentImportContext.BeginImportOverride()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.BaseImportContext.BeginImport(Stream pdfFileStream)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.PdfImporter.Import(Stream input, IPdfImportContext context)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.PdfFormatProvider.<>c__DisplayClass19_0.<ImportOverride>b__0()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.ExceptionHandling.ExecutionHandler.TryHandleExecution[E](Action operation)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.PdfFormatProvider.ImportOverride(Stream input, CancellationToken cancellationToken)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.PdfFormatProvider.ImportOverride(Stream input)
at Telerik.Windows.Documents.Common.FormatProviders.FormatProviderBase`1.Import(Stream input)
at Telerik.Windows.Documents.Common.FormatProviders.BinaryFormatProviderBase`1.Import(Byte[] input)
I have attached the PDF I'm trying to import.