Currently, RadPdfViewer offers the DataError event which is purposed to handle errors during the import process. However, if there are problematic pages that are rendered in the viewer at a later moment after the document is already imported, the viewer doesn't offer a suitable way for handling such problematic moments even though the PdfProcessing library throws one of its exceptions.
The exact client's case is loading a PDF document which contains images requiring JPX Decoder which is currently not supported. Even though the PdfProcessing library throws internally the following error, the RadPdfViewer control doesn't throw the DataError event with the respective error:
Telerik.Windows.Documents.Fixed.Exceptions.NotSupportedFilterException: 'JPXDecode is not supported.'
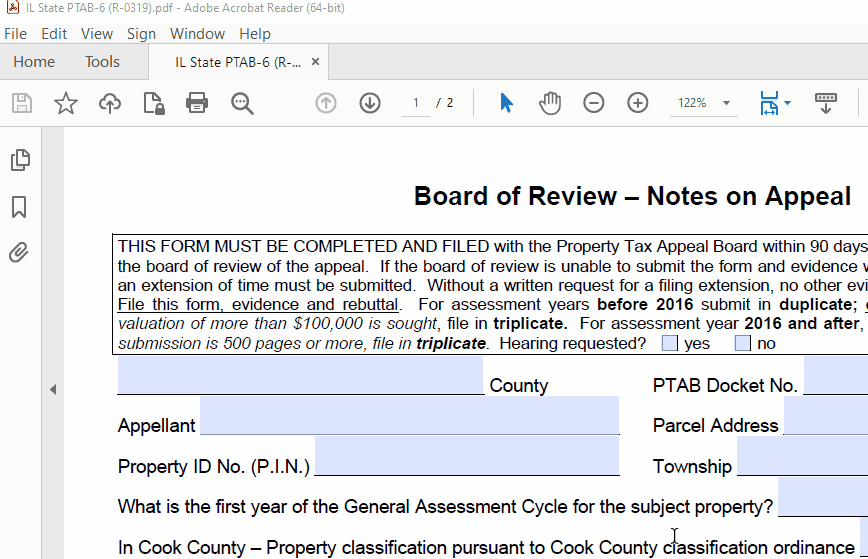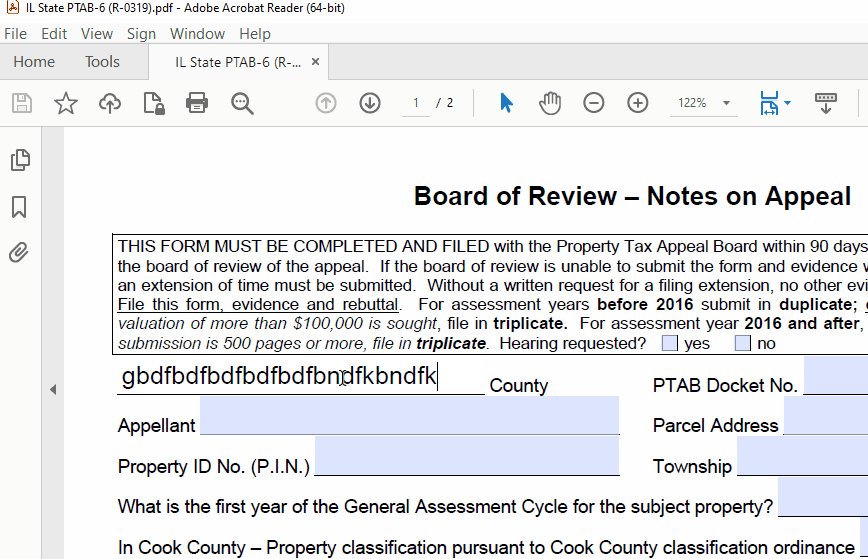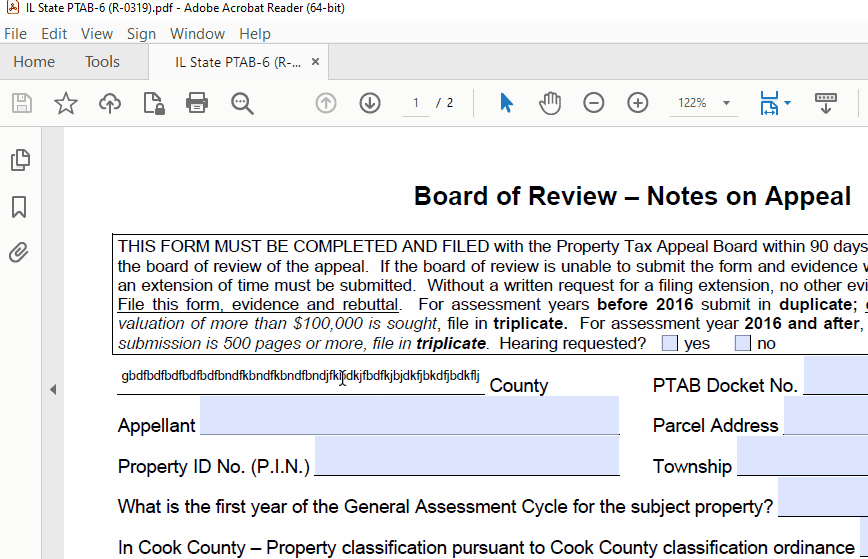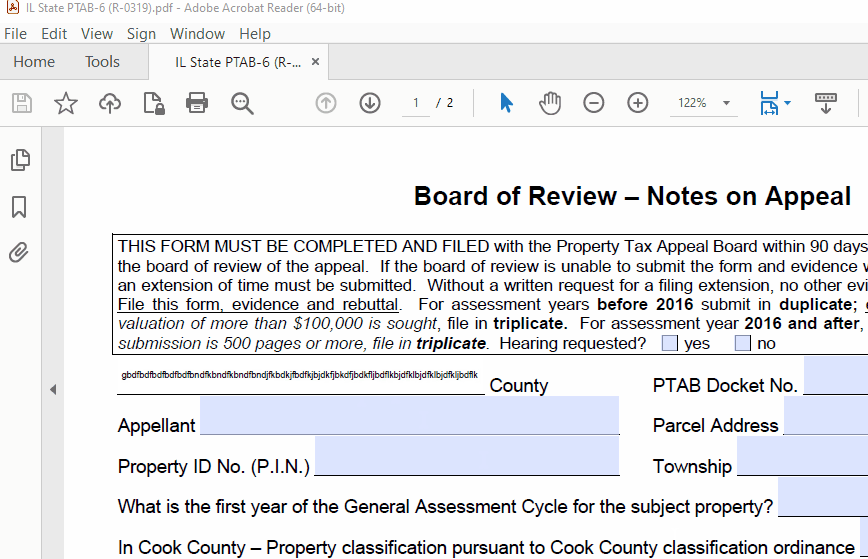
Add functionality for a PDF form filler that supports text auto-sizing/shrinking like Adobe:
The current implementation relies on valid cross-reference table offsets in the PDF documents so that PDF objects are easily found and parsed. However, a mechanism for importing documents with invalid cross-reference table offsets may be implemented.
The attached project shows how to repair such documents.