Import the following HTML content and export it to DOCX format:
<p>Here is my list</p>
<ol start="108" style="list-style-type: lower-latin;">
<li>Item 1</li>
<li>Item 2</li>
</ol>Expected result:

Actual result:

When converting HTML to DOCX, margins set on an HTML element are ignored. These styles are exported correctly when the HTML passed to the converter is formatted with indents. The following XUnit test demonstrates this behavior with a simplified example.
using Telerik.Windows.Documents.Flow.FormatProviders.Docx;
using Telerik.Windows.Documents.Flow.FormatProviders.Html;
namespace MSPI.Tests.Unit;
public class WordExportTest
{
[Fact]
public async Task TextExport()
{
const string formattedDocumentSavePath = @"C:\Testing\export-test-formatted.docx";
const string formattedContent = """"
<p>Test paragraph</p>
<ol style="margin-left: 100px;">
<li>Item 1</li>
<li>Item 2</li>
</ol>
"""";
const string minifiedDocumentSavePath = @"C:\Testing\export-test-minified.docx";
const string minifiedContent = """"<p>Test paragraph</p><ol style="margin-left: 100px;"><li>Item 1</li><li>Item 2</li></ol>"""";
var htmlFormatProvider = new HtmlFormatProvider();
var docxFormatProvider = new DocxFormatProvider();
await using var minifiedDocumentMemoryStream = new MemoryStream();
var minifiedRadFlowDocument = htmlFormatProvider.Import(minifiedContent, TimeSpan.FromSeconds(30));
docxFormatProvider.Export(minifiedRadFlowDocument, minifiedDocumentMemoryStream, TimeSpan.FromSeconds(30));
var minifiedBytes = minifiedDocumentMemoryStream.ToArray();
await File.WriteAllBytesAsync(minifiedDocumentSavePath, minifiedBytes);
await using var formattedDocumentMemoryStream = new MemoryStream();
var formattedRadFlowDocument = htmlFormatProvider.Import(formattedContent, TimeSpan.FromSeconds(30));
docxFormatProvider.Export(formattedRadFlowDocument, formattedDocumentMemoryStream, TimeSpan.FromSeconds(30));
var formattedBytes = formattedDocumentMemoryStream.ToArray();
await File.WriteAllBytesAsync(formattedDocumentSavePath, formattedBytes);
}
}The minified HTML produces the following document:
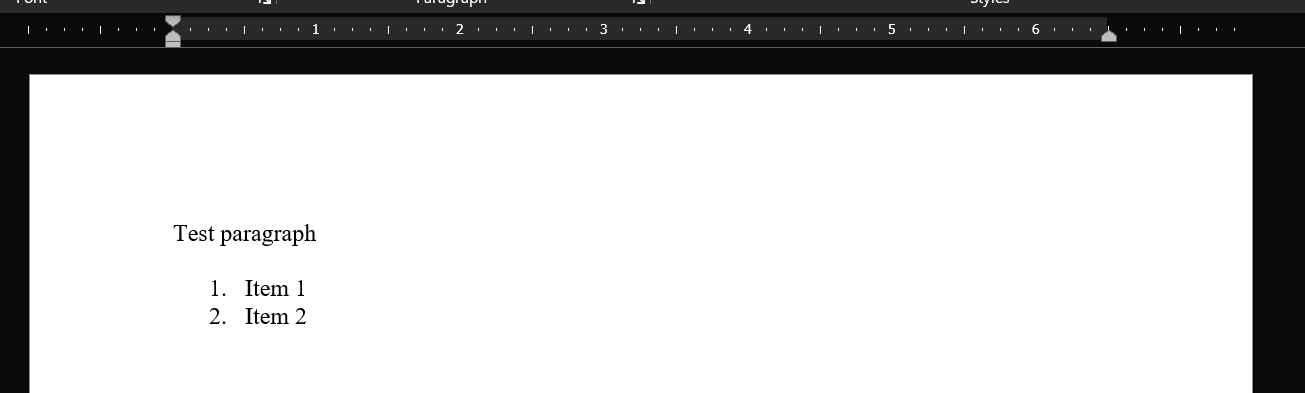
The formatted HTML produces the following document:

Read the documentation for CancelationTokenSource.CancelAfter:
this method will throw an ArgumentOutOfRangeException when: delay.TotalMilliseconds is less than -1 or greater than Int32.MaxValue (or UInt32.MaxValue - 1 on some versions of .NET). Note that this upper bound is more restrictive than TimeSpan.MaxValue.
----------------------------------------------------
your code in CancelationTokenSourceFactory.CreateTokenSource does this check:
if (timeSpan.HasValue && timeSpan.Value != TimeSpan.MaxValue)this check for TimeSpan.MaxValue seems totally pointless here, if timeSpan is anything between ~2147483647 and 922337203685476 milliseconds long this will still just throw a ArgumentOutOfRangeException.
I suspect that this check was intended as a way to prevent creating a cancellation timer that never triggers in the CancellationTokenSource, which should look like this:
if (timeSpan.HasValue && timeSpan != Timeout.InfiniteTimeSpan) //Timeout.InfiniteTimeSpan is -1 millisecondsNullReferenceException when inserting a document containing a table with a document variable having a line break (\n) in its value.
at System.ThrowHelper.ThrowArgumentNullException(ExceptionArgument argument) at System.Collections.Generic.Dictionary`2.FindValue(TKey key) at System.Collections.Generic.Dictionary`2.ContainsKey(TKey key) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Model.Elements.Worksheets.ConditionalFormattingRuleElementX14.OnAfterRead(IXlsxWorksheetImportContext context) in C:\Work\document-processing\Documents\Spreadsheet\FormatProviders\OpenXml\Xlsx\Model\Elements\Worksheets\ConditionalFormatting\x14\ConditionalFormattingRuleElementX14.cs:line 62
Error message:
System.InvalidCastException: 'Unable to cast object of type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Forms.FormFieldsTree' to type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfArray'.'Error message:
System.InvalidCastException: 'Unable to cast object of type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfArray' to type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Functions.FunctionObject'.'Import a document that contains a picture content control and the following error occurs:
Telerik.Windows.Documents.Flow.Model.Annotations.StructuredDocumentTags.Builders.SdtBuilderFailureException: 'Picture control cannot be used in selection that contains any non-image content, or more than a single image.'
Multiple CSS classes on an element are not correctly resolved when converted to inline styles.
Before:
.TelerikNormal {font-family: Calibri;font-size: 14.6666666666667px;margin-top: 0px;margin-bottom: 0px;line-height: 100%;color: #000000;}.TelerikHeading3 {font-family: Calibri Light;font-size: 22.6666666666667px;}<p class="TelerikNormal TelerikHeading3"><span>Test</span></p>Due to order priority, the TelerikHeading3 values override the TelerikNormal values. The font-size becomes 22.6666666666667px.
Convert:
provider.ExportSettings.StylesExportMode = StylesExportMode.Inline;
<p style="font-family: Calibri;font-size: 14.6666666666667px;margin-top: 0px;margin-bottom: 0px;line-height: 100%;color: #000000;"><span>Test</span></p>
using Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Streaming;
using Telerik.Windows.Documents.Fixed.Model.Editing;
using Telerik.Windows.Documents.Fixed.Model.InteractiveForms;
using Telerik.Windows.Documents.Fixed.Model;
using Telerik.Documents.Primitives;
using System.Diagnostics;
using System.Reflection.Metadata;
using Telerik.Windows.Documents.Fixed.FormatProviders.Pdf;
namespace _1681158PdfInputFields
{
internal class Program
{
static void Main(string[] args)
{
ExportExamplePdfForm();
}
public static void ExportExamplePdfForm()
{
RadFixedDocument fixedDoc = new RadFixedDocument();
RadFixedPage fixedPage = fixedDoc.Pages.AddPage();
FixedContentEditor editor = new FixedContentEditor(fixedPage);
editor.Position.Translate(100, 100);
TextBoxField textBox = new TextBoxField("textBox");
fixedDoc.AcroForm.FormFields.Add(textBox);
textBox.Value = "Sample text...";
Size widgetDimensions = new Size(200, 30);
DrawNextWidgetWithDescription(editor, "TextBox", (e) => e.DrawWidget(textBox, widgetDimensions));
string fileName = "output.pdf";
File.Delete(fileName);
// File.WriteAllBytes(fileName, new PdfFormatProvider().Export(fixedDoc, TimeSpan.FromSeconds(15)));
string ResultFileName = "result.pdf";
File.Delete(ResultFileName);
using (PdfStreamWriter writer = new PdfStreamWriter(File.OpenWrite(ResultFileName)))
{
foreach (RadFixedPage page in fixedDoc.Pages)
{
writer.WritePage(page);
}
}
ProcessStartInfo psi = new ProcessStartInfo()
{
FileName = ResultFileName,
UseShellExecute = true
};
Process.Start(psi);
Console.WriteLine("Document created.");
}
private static void DrawNextWidgetWithDescription(FixedContentEditor editor, string description, Action<FixedContentEditor> drawWidgetWithEditor)
{
double padding = 20;
drawWidgetWithEditor(editor);
Size annotationSize = editor.Root.Annotations[editor.Root.Annotations.Count - 1].Rect.Size;
double x = editor.Position.Matrix.OffsetX;
double y = editor.Position.Matrix.OffsetY;
Block block = new Block();
block.TextProperties.FontSize = 20;
block.VerticalAlignment = Telerik.Windows.Documents.Fixed.Model.Editing.Flow.VerticalAlignment.Center;
block.InsertText(description);
editor.Position.Translate(x + annotationSize.Width + padding, y);
editor.DrawBlock(block, new Size(editor.Root.Size.Width, annotationSize.Height));
editor.Position.Translate(x, y + annotationSize.Height + padding);
}
}
}