Recently Updated
Unplanned
Last Updated:
29 Sep 2020 11:38
by ADMIN
Created by:
Ghyslain
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
The provider can be extended so that the users can choose between exporting the font styles with CSS styling or with HTML tags. Currently, the content can be exported with styles only.
Completed
Last Updated:
25 Sep 2020 14:08
by ADMIN
Release R3 2020 SP1
Created by:
Laurent
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
When the associated document style is not of type StyleType.Table (does not contain TableProperties) a NullReferenceException is thrown.
Unplanned
Last Updated:
24 Sep 2020 06:07
by ADMIN
Created by:
BDH
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
There are 27 types of border styles in the Open XML specification and they are implemented in RadFlowDocument. Part of the borders are already supported (eg. None, Single, Dotted) when exporting to HTML, all others are treated as None and stripped.
The HTML format doesn't support all types of border styles OOXML format supports.
Unplanned
Last Updated:
23 Sep 2020 13:23
by ADMIN
Created by:
César
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
Such objects are defined as oleObject elements in the XML:
<w:object w:dxaOrig="3795" w:dyaOrig="3555">
<v:shape id="_x0000_i1026" type="#_x0000_t75" style="width:32.85pt;height:30.55pt" o:ole="" fillcolor="window">
<v:imagedata r:id="rId9" o:title=""/>
</v:shape>
<o:OLEObject Type="Embed" ProgID="PBrush" ShapeID="_x0000_i1026" DrawAspect="Content" ObjectID="_1647182330" r:id="rId10"/>
</w:object>Currently, they are skipped on import.
Unplanned
Last Updated:
18 Sep 2020 05:47
by ADMIN
Created by:
Dimitar
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
Introduce support for the "page-break-inside" tag when importing an HTML
Unplanned
Last Updated:
11 Sep 2020 10:01
by ADMIN
Created by:
Dimitar
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
The negative margin is not respected when exporting to pdf.
Unplanned
Last Updated:
12 Aug 2020 06:54
by ADMIN
Created by:
SPARE GmbH
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
Wrongly imported/exported table cells from nested tables (see the picture below).
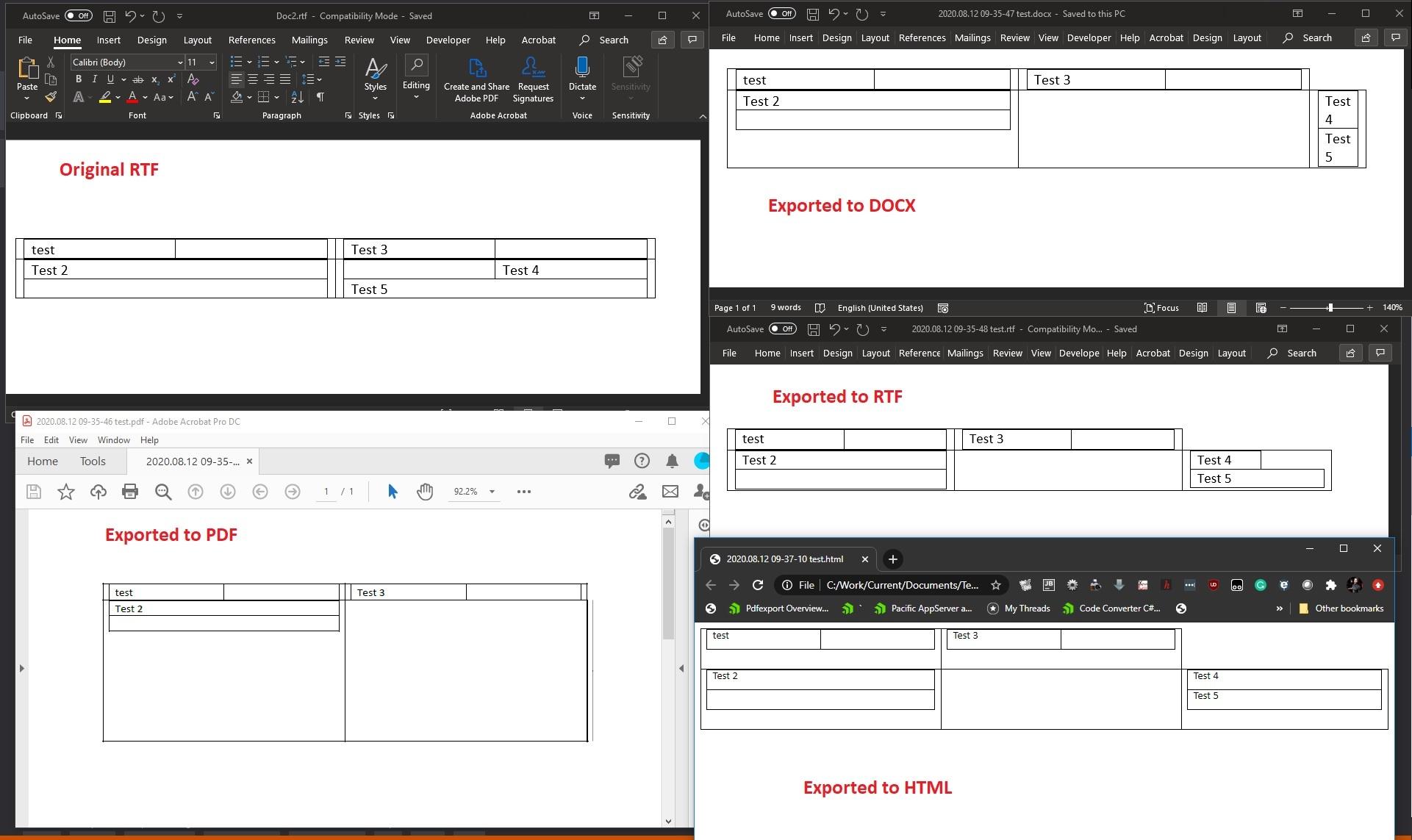
Unplanned
Last Updated:
31 Jul 2020 06:39
by ADMIN
Created by:
Dimitar
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
Right alignment in a table does not work when converting from html to pdf
Completed
Last Updated:
29 Jul 2020 07:04
by ADMIN
Release R3 2020
Created by:
John
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
ArgumentException is thrown when importing an RTF document which has a font size is set to zero (\fs0).
Completed
Last Updated:
28 Jul 2020 13:55
by ADMIN
Release R3 2020
ADMIN
Created by:
Polya
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
The exception is thrown because the AltChunk element is added for import, but we currently do not have implementation for importing of AltChunk elements: https://feedback.telerik.com/Project/184/Feedback/Details/190095-wordsprocessing-add-support-for-altchunk-element
Unplanned
Last Updated:
28 Jul 2020 08:02
by ADMIN
Created by:
Mike
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
There is a discrepancy between RadWordsProcessing and MS Word:
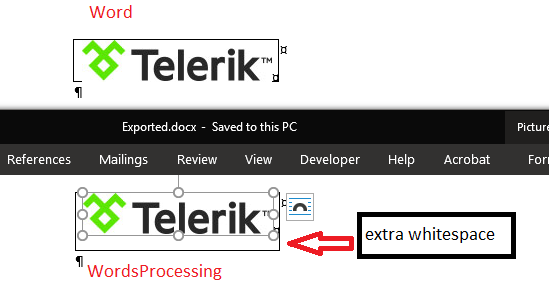
row.Height = new TableRowHeight(HeightType.Exact, image.Image.Height);
Unplanned
Last Updated:
22 Jul 2020 12:19
by ADMIN
Created by:
Dimitar
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
The exported rtf file is not valid and cannot be imported when converting from HTML.
Unplanned
Last Updated:
21 Jul 2020 08:29
by ADMIN
Created by:
Dimitar
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
The background color is not exported to pdf
Unplanned
Last Updated:
17 Jul 2020 08:39
by ADMIN
Created by:
David
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
Provide an API for getting the CellType value in order to check if the cell in a row is of type Header/Body.
Completed
Last Updated:
03 Jul 2020 08:07
by ADMIN
Release R3 2020
Created by:
Chandra
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
Font properties set from RadFlowDocumentEditor`s CharacterFormatting are not taken into account when inserting PAGE field:
editor.InsertField("PAGE", "1")
Unplanned
Last Updated:
02 Jul 2020 13:37
by ADMIN
Created by:
Marcel
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
A possible workaround could be to remove the image with the invalid Uri from the RadFlowDocument before export:
foreach (ImageInline image in document.EnumerateChildrenOfType<ImageInline>().ToList())
{
UriImageSource uriImageSource = (UriImageSource)image.Image.ImageSource;
if (uriImageSource != null && !IsValid(uriImageSource.Uri.OriginalString))
{
image.Paragraph.Inlines.Remove(image);
}
}private static bool IsValid(string uri)
{
try
{
Path.GetExtension(uri);
}
catch (ArgumentException)
{
return false;
}
return true;
}
Completed
Last Updated:
02 Jul 2020 13:22
by ADMIN
Release R3 2020
ADMIN
Created by:
Tanya
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
Importing shape with missing id attribute leads to NullReferenceException. <v:shape type="#_x0000_t202" filled="false" stroked="false">
Completed
Last Updated:
02 Jul 2020 13:13
by ADMIN
Release R3 2020
ADMIN
Created by:
Deyan
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
Table and table cell borders are not evaluated according to inheritance and conflict resolution rules. A conflict will occur when different borders from the table and table cell are overlapping. The GetActualValue method of the TableBorders and TableCellBorders could potentially return an incorrect value in some of the following scenarios: Scenario 1: A table has cell spacing set to 0. Meaning that the table and table cell borders will overlap. The table borders have defined all of its borders with border style "Single". The table cell borders have all of its borders defined with border style "None". Expected result: the resulting borders should have the border style set to "None" for the location where the table and the cell borders are overlapping. Scenario 2: A table has explicitly defined that its right border is with border style "None". The table has a table style applied with defined border style of type "Single" for all table borders. Expected result: All of the table borders except the right border should have border style of "Single". The problem is mostly visible when exporting to PDF and RTF format.
Completed
Last Updated:
04 Jun 2020 09:42
by ADMIN
Release R2 2020 SP1
Created by:
John
Comments:
3
Category:
WordsProcessing
Type:
Bug Report
KeyNotFoundException is thrown when importing RTF document which has an invalid Font Family name.
Completed
Last Updated:
03 Jun 2020 10:51
by ADMIN
Release R2 2020 SP1
Created by:
Dimitar
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
The empty lines are not converted properly from RTF to HTML
Workaround:
private static void FixEmptyParagraphs(RadFlowDocument document){
var paragraphs = document.EnumerateChildrenOfType<Paragraph>();
foreach (var paragraph in paragraphs)
{
if (paragraph.Inlines.Count < 1)
{
char nbsp = (char)160;
paragraph.Inlines.AddRun(nbsp.ToString());
}
}
}