Import the following HTML content and export it to DOCX format:
<p>Here is my list</p>
<ol start="108" style="list-style-type: lower-latin;">
<li>Item 1</li>
<li>Item 2</li>
</ol>Expected result:

Actual result:

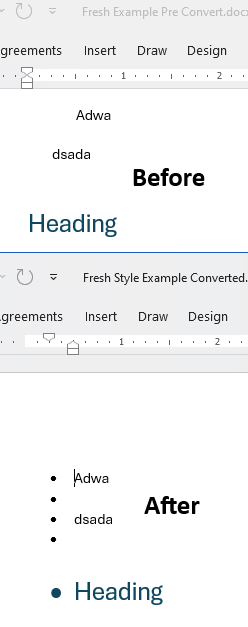
Paragraphs with a bulleted "Normal" style, but with bullets removed inline, revert to showing bullets after import/export with Telerik Document Processing (DPL)—is not the intended behavior. Inline overrides, such as manually removing bullets from specific paragraphs, should be preserved after processing:
RadFlowDocumentEditor.InsertDocument throws NullReferenceException when inserting a document with incorrectly paired permission range elements.
Valid (Nested):
<w:permStart w:id="1"/>
<w:permStart w:id="2"/>
... content ...
<w:permEnd w:id="2"/>
<w:permEnd w:id="1"/>Invalid (Overlapped):
<w:permStart w:id="1"/>
<w:permStart w:id="2"/>
<w:permEnd w:id="1"/>
<w:permEnd w:id="2"/>Workaround - Remove all Permission Ranges before inserting:
var startPermissionRanges = contentDocument.EnumerateChildrenOfType<PermissionRangeStart>().ToList();
var endPermissionRanges = contentDocument.EnumerateChildrenOfType<PermissionRangeEnd>().ToList();
foreach (PermissionRangeStart rangeStart in startPermissionRanges)
{
rangeStart.Paragraph.Inlines.Remove(rangeStart);
}
foreach (PermissionRangeEnd rangeEnd in endPermissionRanges)
{
rangeEnd.Paragraph.Inlines.Remove(rangeEnd);
}
When imported in the WordsProcessing model, the current HTML doesn't respect the defined column width and all columns have identical width:
<colgroup>
<col span="1" style="width: 33.3302%;">
<col span="1" style="width: 17.5658%;">
<col span="1" style="width: 49.104%;">
</colgroup>Observed result:

Expected result:

Workaround: use the width property as follows:
<colgroup>
<col span="1" width="33.3302%">
<col span="1" width="17.5658%">
<col span="1" width="49.104%">
</colgroup>
When importing HTML content to a RadFlowDocument and exporting it to PDF format, the following error message occurs:
System.ArgumentException: 'The document element is associated with another parent. (Parameter 'item')'
at Telerik.Windows.Documents.Fixed.Model.Collections.DocumentElementCollection`2.VerifyDocumentElementOnInsert(T item)at Telerik.Windows.Documents.Core.Data.DocumentElementCollectionBase`2.Add(T item)
at Telerik.Windows.Documents.Fixed.Model.Editing.FixedContentEditor.Append(PositionContentElement element)
at Telerik.Windows.Documents.Fixed.Model.Editing.FixedContentEditor.Draw(PositionContentElement element)
at Telerik.Windows.Documents.Fixed.Model.Editing.Layout.ContentElementLayoutElementBase`1.Draw(DrawLayoutElementContext context)
at Telerik.Windows.Documents.Fixed.Model.Editing.Block.Draw(IEnumerable`1 lineElements, DrawLayoutElementContext context)
at Telerik.Windows.Documents.Fixed.Model.Editing.Block.DrawInternal(FixedContentEditor editor, Rect boundingRect)
at Telerik.Windows.Documents.Fixed.Model.Editing.Block.Draw(FixedContentEditor editor, Rect boundingRect)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.TableCell.Draw(FixedContentEditor editor)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.Table.DrawCellContent(FixedContentEditor editor, TableCell cell)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.Table.DrawTableCells(FixedContentEditor editor, Int32 rowIndex, TableCellCollection cells)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.Table.DrawTableRows(FixedContentEditor editor)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.Table.DrawInternal(FixedContentEditor editor, Rect boundingRect)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.Table.Draw(FixedContentEditor editor, Rect boundingRect)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.TableCell.Draw(FixedContentEditor editor)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.Table.DrawCellContent(FixedContentEditor editor, TableCell cell)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.Table.DrawTableCells(FixedContentEditor editor, Int32 rowIndex, TableCellCollection cells)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.Table.DrawTableRows(FixedContentEditor editor)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.Table.DrawInternal(FixedContentEditor editor, Rect boundingRect)
at Telerik.Windows.Documents.Fixed.Model.Editing.Tables.Table.Telerik.Windows.Documents.Fixed.Model.Editing.Flow.IDrawArrangedElement.DrawArrangedElement(FixedContentEditor editor, Rect boundingRect)
at Telerik.Windows.Documents.Fixed.Model.Editing.Flow.SectionInfo.DrawArrangedElement(IBlockElement blockElement, Double horizontalOffset, Double verticalOffset)
at Telerik.Windows.Documents.Fixed.Model.Editing.Utils.SectionInfoExtensions.DrawArrangedElements(SectionInfo section, IList`1 elements)
at Telerik.Windows.Documents.Fixed.Model.Editing.RadFixedDocumentEditor.Draw()
at Telerik.Windows.Documents.Fixed.Model.Editing.RadFixedDocumentEditor.StartNewPage(SectionProperties sectionProperties)
at Telerik.Windows.Documents.Fixed.Model.Editing.RadFixedDocumentEditor.StartNewPage()
at Telerik.Windows.Documents.Fixed.Model.Editing.RadFixedDocumentEditor.AddBlock(IBlockElement blockElement, CancellationToken cancellationToken)
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.Export.PdfExporter.ExportSection(Section section, RadFixedDocumentEditor editor)
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.Export.PdfExporter.ExportDocument(RadFlowDocument document, RadFixedDocumentEditor editor)
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.Export.PdfExporter.ExportInternal()
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.Export.PdfExporter.Export()
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.PdfFormatProvider.ExportToFixedDocument(RadFlowDocument document, CancellationToken cancellationToken)
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.PdfFormatProvider.ExportOverride(RadFlowDocument document, Stream output, CancellationToken cancellationToken)
at Telerik.Windows.Documents.Common.FormatProviders.FormatProviderBase`1.Export(T document, Stream output, Nullable`1 timeout)
at _1713205HtmlToPdf.Program.Main(String[] args) in C:\Users\dyordano\OneDrive - Progress Software Corporation\MyProjects\1713205HtmlToPdf\Program.cs:line 46
When the document is encoded in two-byte encoding using Little-Endian, the CsQuery HTML parser provides the entire document as FirstChild of the <body> tag, which leads to incorrect import. This seems to be occurring with MS Outlook messages saved as HTML. Workaround: convert the file to Big-Endian encoding before importing.
The item is closed as duplicate. Please, submit your votes and subscribe for notifications to the item at https://feedback.telerik.com/Project/184/Feedback/Details/190053-wordsprocessing-support-for-importing-dotm-dotx-and-docm-files.
Hyperlinks should support this property in order to describe where they should be opened (in the same frame/tab or in a new one). It is described in the OOXML specification as tgtFrame (Hyperlink Target Frame). It will be useful for setting the target as _blank.
When importing from HTML, all successive spaces in a spans are trimmed. Instead, in some cases one space should be left, e.g. between words. For example, the importing the following HTML should leave one space after the hyperlink:
<p><a href="www.telerik.com" target="_blank"><span>test</span></a> and more.</p>
Workaround: After importing, check if the runs after the hyperlinks start with space:
foreach (var hyperlinkEnd in this.document.EnumerateChildrenOfType<FieldCharacter>().Where(f => f.FieldCharacterType == FieldCharacterType.End))
{
Paragraph currentParagraph = hyperlinkEnd.Paragraph;
int indexOfNextRun = currentParagraph.Inlines.IndexOf(hyperlinkEnd) + 1;
if (currentParagraph.Inlines.Count > indexOfNextRun)
{
Run run = currentParagraph.Inlines[indexOfNextRun] as Run;
if (run != null && run.Text[0] != ' ')
{
run.Text = " " + run.Text;
}
}
}
When paragraphs in list and with hanging indent set are imported from RTF, unexpected values for hanging indent and left indent are imported. The problem is most visible when the document is exported to HTML and visualized in browser, as bullets of the list appear over the content.
ArgumentException with 'Invalid value' message is thrown when importing invalid font sizes from docx, e.g. <w:sz></w:sz> (the 'val' attribute should be specified according to the OOXML specification). Instead, such documents could be imported as the w:sz is not specified, similar to the behavior of MS Word.
This is done due to wrong column widths weights calculations.
The tblGrid property should be exported in order to visualize properly the documents in some viewers. For example, LibreOffice doesn't visualize properly tables without specified width.