Unplanned
Last Updated:
03 Mar 2025 09:09
by Vijayaprasad
Created by:
Vijayaprasad
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
Preserve the comments when exporting the DOCX file to PDF format
Unplanned
Last Updated:
11 Jul 2025 09:57
by Jennifer
Created by:
Jennifer
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
This is the code for generating the document from scratch:
static void Main(string[] args)
{
Telerik.Windows.Documents.Flow.Model.RadFlowDocument document = CreateDocument();
Telerik.Windows.Documents.Flow.FormatProviders.Docx.DocxFormatProvider provider = new Telerik.Windows.Documents.Flow.FormatProviders.Docx.DocxFormatProvider();
string outputFilePath = "output.docx";
File.Delete(outputFilePath);
using (Stream output = File.OpenWrite(outputFilePath))
{
provider.Export(document, output, TimeSpan.FromSeconds(10));
}
Process.Start(new ProcessStartInfo() { FileName = outputFilePath, UseShellExecute = true });
}
//Not working example
private static RadFlowDocument CreateDocument()
{
int FullPercentWidth = 100;
var document = new RadFlowDocument();
var editor = new RadFlowDocumentEditor(document);
editor.InsertSection();
var header = document.Sections.First().Headers.Add().Blocks.AddParagraph();
header.TextAlignment = Alignment.Center;
editor.MoveToParagraphStart(header);
editor.InsertLine("Dissemination Label");
var br = new Break(document);
header.Inlines.Add(br);
editor.MoveToParagraphEnd(header);
editor.InsertText("Test");
editor.MoveToParagraphStart(document.Sections.First().Blocks.AddParagraph());
editor.InsertParagraph();
editor.InsertLine("First Header");
editor.InsertLine("Second Header");
editor.TableFormatting.StyleId = BuiltInStyleNames.TableGridStyleId;
document.StyleRepository.AddBuiltInStyle(BuiltInStyleNames.TableGridStyleId);
Table table = editor.InsertTable();
table.PreferredWidth = new TableWidthUnit(TableWidthUnitType.Percent, FullPercentWidth);
table.LayoutType = TableLayoutType.AutoFit;
TableRow headerRow = table.Rows.AddTableRow();
var cell = headerRow.Cells.AddTableCell();
var cellParagraph = cell.Blocks.AddParagraph();
_ = cellParagraph.Inlines.AddRun("ID");
var cell2 = headerRow.Cells.AddTableCell();
var cellParagraph2 = cell2.Blocks.AddParagraph();
_ = cellParagraph2.Inlines.AddRun("Title");
var cell3 = headerRow.Cells.AddTableCell();
var cellParagraph3 = cell3.Blocks.AddParagraph();
_ = cellParagraph3.Inlines.AddRun("Page Number");
for (var i = 0; i < 3; i++)
{
var dataRow = table.Rows.AddTableRow();
string id = "ID-" + i;
var cell4 = dataRow.Cells.AddTableCell();
var cellParagraph4 = cell4.Blocks.AddParagraph();
_ = cellParagraph4.Inlines.AddRun(id);
var cell5 = dataRow.Cells.AddTableCell();
var cellParagraph5 = cell5.Blocks.AddParagraph();
_ = cellParagraph5.Inlines.AddRun($"Fake Title {i}");
var cell6 = dataRow.Cells.AddTableCell();
var cellParagraph6 = cell6.Blocks.AddParagraph();
editor.MoveToParagraphStart(cellParagraph6);
editor.InsertField($"PAGEREF bookmark-{id}", string.Empty);
}
for (var i = 0; i < 3; i++)
{
var id = "ID-" + i;
var section = document.Sections.AddSection();
section.SectionType = SectionType.NextPage;
var header2 = document.Sections.Count == 1
? document.Sections.AddSection().Headers.Add().Blocks.AddParagraph()
: document.Sections.Last().Headers.Add().Blocks.AddParagraph();
editor.MoveToParagraphStart(header2);
editor.InsertLine("Dissemination Label");
editor.InsertBreak(BreakType.LineBreak);
editor.InsertLine("Fake Header");
editor.InsertText("Display name");
var table2 = new Table(document)
{
PreferredWidth = new TableWidthUnit(TableWidthUnitType.Percent, FullPercentWidth),
LayoutType = TableLayoutType.AutoFit
};
var headerRow2 = table2.Rows.AddTableRow();
headerRow2.CanSplit = false;
var headerCell = headerRow2.Cells.AddTableCell();
var headerParagraph = headerCell.Blocks.AddParagraph();
headerParagraph.Inlines.AddRun("Title").FontWeight = FontWeights.Bold;
headerParagraph.Spacing.SpacingAfter = 0;
headerCell.ColumnSpan = 3;
table2.LayoutType = TableLayoutType.FixedWidth;
var row = InsertRow(table2);
var cell7 = row.Cells.AddTableCell();
var cellParagraph7 = cell7.Blocks.AddParagraph();
_ = cellParagraph7.Inlines.AddRun("Stuff and things");
var cell8 = row.Cells.AddTableCell();
var cellParagraph8 = cell8.Blocks.AddParagraph();
_ = cellParagraph8.Inlines.AddRun($"Stuff and things-{id}");
editor.InsertBookmark($"bookmark-{id}");
_ = InsertRow(table2);
_ = InsertRow(table2);
document.Sections.Last().Blocks.Add(table2);
var table3 = new Table(document)
{
PreferredWidth = new TableWidthUnit(TableWidthUnitType.Percent, FullPercentWidth),
LayoutType = TableLayoutType.AutoFit
};
var fakeText = "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed laoreet finibus nulla sit amet consectetur. Fusce dignissim sapien congue augue hendrerit, eu rutrum orci lacinia. Maecenas sit amet augue ut arcu consequat molestie ac pretium nulla. Donec venenatis rhoncus pulvinar. Aliquam vel est vitae lacus porta aliquam. Morbi aliquet vulputate turpis, ut vulputate elit accumsan at. Vivamus interdum dictum arcu vel euismod. Curabitur commodo eu nisi ut ultrices. Duis at auctor eros. Vivamus et metus ligula. Vestibulum feugiat velit a feugiat sodales. Sed vitae urna sodales, faucibus felis non, sagittis diam.\r\n\r\nPraesent turpis est, aliquet consectetur felis et, pharetra placerat ipsum. Sed at consectetur metus. Integer dictum iaculis libero, interdum vehicula ipsum convallis a. Orci varius natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Sed pretium ac quam id finibus. Maecenas bibendum magna vel rhoncus eleifend. Etiam nec ante nulla. Etiam lacinia vulputate quam, et ullamcorper magna fermentum quis. Suspendisse potenti. Quisque quis nulla non velit lacinia laoreet. Fusce et lacinia enim, sit amet rhoncus eros. Etiam placerat fringilla nibh ac commodo.\r\n\r\nMorbi ac commodo elit. Sed a leo quis sem convallis volutpat eget et nunc. In laoreet eleifend ullamcorper. Phasellus pharetra molestie eleifend. Cras consequat risus ac est accumsan sagittis. Suspendisse facilisis ultrices ipsum, vitae porttitor augue tincidunt ac. Ut sagittis nisl tristique efficitur aliquam. Pellentesque molestie mauris id ipsum lacinia, a vehicula eros molestie. Aliquam quis sagittis tellus.";
for (var j = 0; j < 2; j++)
{
var row2 = InsertRow(table3);
var cell9 = row2.Cells.AddTableCell();
var cellParagraph9 = cell9.Blocks.AddParagraph();
_ = cellParagraph9.Inlines.AddRun(fakeText);
}
document.Sections.Last().Blocks.Add(table3);
}
FlowExtensibilityManager.NumberingFieldsProvider = new NumberingFieldsProvider();
foreach (var s in document.Sections)
{
s.Footers.Add();
Footer f = s.Footers.Default;
Paragraph paragraph = f.Blocks.AddParagraph();
paragraph.TextAlignment = Alignment.Right;
editor.MoveToParagraphStart(paragraph);
editor.InsertText("Page ");
editor.InsertField("PAGE", string.Empty);
editor.InsertText(" of ");
editor.InsertField("NUMPAGES", string.Empty);
var paragrpah2 = s.Blocks.AddParagraph();
editor.MoveToParagraphStart(paragrpah2);
}
document.UpdateFields();
return document;
}
private static TableRow InsertRow(Table table)
{
TableRow row = new TableRow(table.Document);
table.Rows.Add(row);
return row;
}
Unplanned
Last Updated:
21 Aug 2025 07:39
by Matt
Created by:
Matt
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
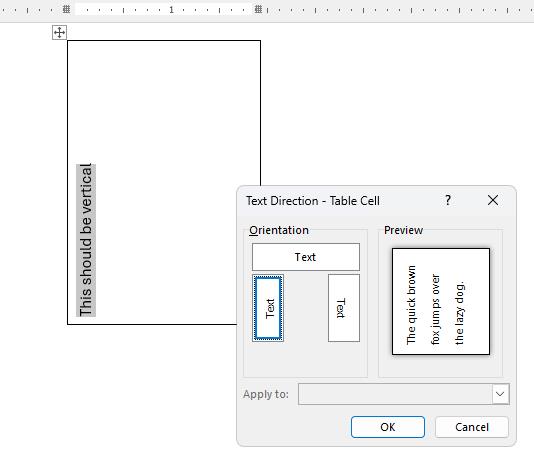
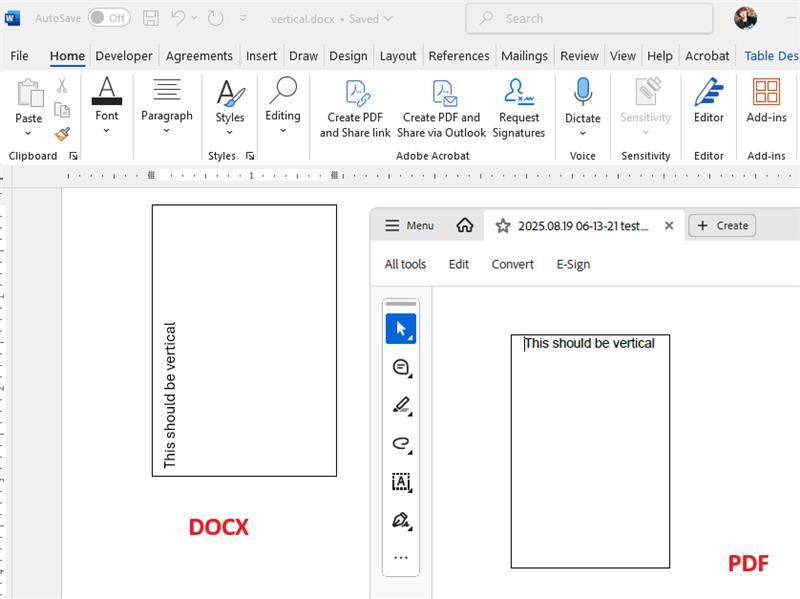
Unplanned
Last Updated:
17 Oct 2025 06:28
by Daniel
Created by:
Daniel
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
Optimize PDFs for quick viewing on the web, especially for mobile clients. Linearization allows your end users to view large PDF documents incrementally so that they can view pages much faster in lower bandwidth conditions: https://developer.adobe.com/document-services/docs/overview/pdf-services-api/howtos/linearize-pdf/
Completed
Last Updated:
08 Jul 2026 07:58
by ADMIN
Release 2026.2.707 (2026 Q2)
Created by:
Maks
Comments:
4
Category:
WordsProcessing
Type:
Bug Report
StackOverflowException is thrown when exporting a document with circular style links when resolving unpopulated style properties.
Completed
Last Updated:
14 May 2026 16:33
by ADMIN
Release 2026.2.514 (2026 Q2)
ADMIN
Created by:
Deyan
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
When a style doesn't have explicitly defined font, the font from the default character properties (\defchp) is used when present. Instead, the font used for the style should be the default font for the document, defined with \deffN tag. The same issue occur when the doesn't contain \defchp at all. In this case, the font for the style is not imported, but instead the defined with \deffN tag should be used. The construction is not common, and MS Word for example doesn't produce such documents.
Declined
Last Updated:
16 Aug 2017 10:52
by ADMIN
ADMIN
Created by:
Deyan
Comments:
1
Category:
WordsProcessing
Type:
Feature Request
Unplanned
Last Updated:
27 Jan 2017 13:51
by ADMIN
ADMIN
Created by:
Deyan
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
When a paragraph has defined tab stops in its style and has the same tab stops locally cleared, the tab stops are still respected when exporting to PDF. Instead, cleared tab stops should not be respected.
Completed
Last Updated:
01 Sep 2021 12:14
by ADMIN
Release R2 2021
ADMIN
Created by:
Deyan
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
According to the OOXML specification the shading color can be defined only in RRGGBB hex color, but MS Word also supports colors defined with their names - e.g. "Red".
Completed
Last Updated:
14 Jun 2016 07:29
by ADMIN
ADMIN
Created by:
Deyan
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
Workaround: Copy the default styles after the Mail Merge RadFlowDocument merged = sourceDocument.MailMerge(mailMergeSource); merged.DefaultStyle.ParagraphProperties.CopyPropertiesFrom(sourceDocument.DefaultStyle.ParagraphProperties); merged.DefaultStyle.CharacterProperties.CopyPropertiesFrom(sourceDocument.DefaultStyle.CharacterProperties);
Completed
Last Updated:
02 Jun 2016 05:09
by ADMIN
ADMIN
Created by:
Deyan
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
If the value from the source contains new lines, they should be inserted in the resulting documents as new paragraphs.
Unplanned
Last Updated:
13 Sep 2017 06:03
by ADMIN
ADMIN
Created by:
Deyan
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
The <font> tag has a 'size' attribute that can be set to a number from 1 to 17. This is currently not supported and is just ignored.
Unplanned
Last Updated:
07 Sep 2017 06:58
by ADMIN
ADMIN
Created by:
Mihail
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
CSS style property with a numeric value will not be imported from HTML when the unit type is not specified. Example: .td{padding-bottom: 200;}
This is invalid according to the HTML spec (value is optional only after 0), though web browsers and MS Word open such HTML's correctly.
Completed
Last Updated:
09 Dec 2020 09:34
by ADMIN
Release LIB 2020.3.1214 (07/14/2020)
ADMIN
Created by:
Todor
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
In specific situations, a paragraph in a table cell which is last on a document page is not exported to the PDF document.
Possible workaround is adding a new paragraph to the last table cell before exporting the document.
For instance:
BlockCollection footerContent = this.document.Sections.First().Footers.Default.Blocks;
Table footerTable = footerContent.First() as Table;
footerTable.Rows.Last().Cells.First().Blocks.AddParagraph();
Completed
Last Updated:
05 Oct 2016 07:01
by ADMIN
ADMIN
Created by:
Tanya
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
Unplanned
Last Updated:
13 Sep 2017 06:30
by ADMIN
ADMIN
Created by:
Mihail
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
Import styling properties from HTML for elements without DocumentElementProperties. For example, for ImageInline: the image has width and height and currently they could not be applied through CSS styling as the styling mechanism works only for document elements with DocumentElementPropertiesBase (RadFlowDocument, Section, Table, Paragraph, etc.)
Unplanned
Last Updated:
08 Sep 2017 05:48
by ADMIN
ADMIN
Created by:
Mihail
Comments:
0
Category:
WordsProcessing
Type:
Feature Request
Implement API allowing to add watermarks without specifying its width and the height. The size could be automatically calculated using the text, its font size and font family.
Unplanned
Last Updated:
16 Aug 2016 11:34
by ADMIN
ADMIN
Created by:
Nikolay Demirev
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
The text of the watermark is exported with the default font family due to incorrect escaping while writing the OpenXML.
Completed
Last Updated:
25 Mar 2022 15:16
by ADMIN
Release R2 2022
ADMIN
Created by:
Mihail
Comments:
1
Category:
WordsProcessing
Type:
Bug Report
Field code fragment is added to the result fragment and exported to PDF/HTML format. The problem is observed when the code fragment is divided into multiple inlines. For example we have PAGE field. If 'A' is bold we would have 3 inlines (runs) in the instruction text and the issue would be observed.
Completed
Last Updated:
15 Aug 2025 13:49
by ADMIN
Release 2025.3.806 (2025 Q3)
ADMIN
Created by:
Mihail
Comments:
0
Category:
WordsProcessing
Type:
Bug Report
An empty paragraph is exported with different font size than the one coming from its style. The character properties should come from the style system. Workaround: Add at least one space in each empty paragraph.