In DOCX, such lines are defined using the legacy VML definitions:
<w:pict w14:anchorId="324D5836">
<v:rect id="_x0000_i1025" style="width:0;height:1.5pt" o:hralign="center" o:hrstd="t" o:hr="t" fillcolor="#a0a0a0" stroked="f"/>
</w:pict>It would be nice to have the ability to search text in documents. Use case: I needed to replace some keywords with images. I can insert image at the current position, but there is no way to insert it after some text.
StackOverflowException is thrown during PDF export of a document with a Header/Footer containing a page break.
Workaround: Remove page break from all header/footer paragraphs, or from a specific paragraph.
Header defaultHeader = section.Headers.Default;
if (defaultHeader != null)
{
foreach (var item in defaultHeader.Blocks)
{
if (item is Paragraph paragraph)
{
paragraph.PageBreakBefore = false;
}
}
}
When imported in the WordsProcessing model, the current HTML doesn't respect the defined column width and all columns have identical width:
<colgroup>
<col span="1" style="width: 33.3302%;">
<col span="1" style="width: 17.5658%;">
<col span="1" style="width: 49.104%;">
</colgroup>Observed result:

Expected result:

Workaround: use the width property as follows:
<colgroup>
<col span="1" width="33.3302%">
<col span="1" width="17.5658%">
<col span="1" width="49.104%">
</colgroup>
Multiple CSS classes on an element are not correctly resolved when converted to inline styles.
Before:
.TelerikNormal {font-family: Calibri;font-size: 14.6666666666667px;margin-top: 0px;margin-bottom: 0px;line-height: 100%;color: #000000;}.TelerikHeading3 {font-family: Calibri Light;font-size: 22.6666666666667px;}<p class="TelerikNormal TelerikHeading3"><span>Test</span></p>Due to order priority, the TelerikHeading3 values override the TelerikNormal values. The font-size becomes 22.6666666666667px.
Convert:
provider.ExportSettings.StylesExportMode = StylesExportMode.Inline;
<p style="font-family: Calibri;font-size: 14.6666666666667px;margin-top: 0px;margin-bottom: 0px;line-height: 100%;color: #000000;"><span>Test</span></p>
In case table cell doesn't have directly applied background, it should inherit the background of its parent table.
This is the code for import/export which result is illustrated below:
string inputFilePath = "test1.doc";
Telerik.Windows.Documents.Flow.Model.RadFlowDocument document;
Telerik.Windows.Documents.Flow.FormatProviders.Doc.DocFormatProvider doc_provider = new Telerik.Windows.Documents.Flow.FormatProviders.Doc.DocFormatProvider();
using (Stream input = File.OpenRead(inputFilePath))
{
document = doc_provider.Import(input, TimeSpan.FromSeconds(10));
}
Telerik.Windows.Documents.Flow.FormatProviders.Docx.DocxFormatProvider docx_provider = new Telerik.Windows.Documents.Flow.FormatProviders.Docx.DocxFormatProvider();
string outputFilePath = "Exported.docx";
using (Stream output = File.OpenWrite(outputFilePath))
{
docx_provider.Export(document, output, TimeSpan.FromSeconds(10));
}
Process.Start(new ProcessStartInfo() { FileName = outputFilePath, UseShellExecute = true });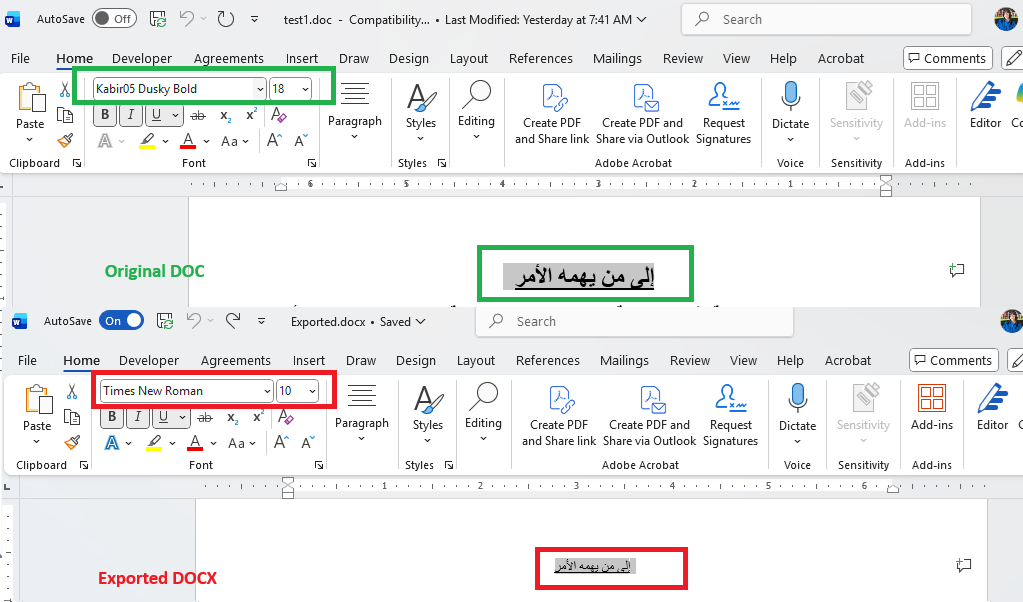
An incorrect file is produced when merging a stream more than 40 times.
Workaround: A possible workaround could be to merge up to 40 times in one file, then continue merging in a new one, and finally merge the newly generated documents.
Unable to open RTF to DOCX-exported document in MS Word due to large tab stop accumulation.
Workaround: Re-save the original RTF file with MS Word before converting it to DOCX.
The DataBinding property tells the editor to show the linked content instead of the actual runs in the content control.
Duplicated with WordsProcessing: Add support for content control values that use data binding.
Text frames are paragraphs of text in a document which are positioned in a separate region or frame in the document and can be positioned with a specific size and position relative to non-frame paragraphs in the current document. More information about it is available in section 22.9.2.18 ST_XAlign (Horizontal Alignment Location) of Open Office XML.
HtmlFormatProvider: Styles are not correctly preserved when a <b> tag is applied to the same styled element.
Workaround: Apply bold through CSS instead of using <b>.
When a style doesn't have explicitly defined font, the font from the default character properties (\defchp) is used when present. Instead, the font used for the style should be the default font for the document, defined with \deffN tag. The same issue occur when the doesn't contain \defchp at all. In this case, the font for the style is not imported, but instead the defined with \deffN tag should be used. The construction is not common, and MS Word for example doesn't produce such documents.