Workaround: Change the widget font:
foreach (Widget widget in textBoxField.Widgets)
{
widget.TextProperties.Font = FontsRepository.Helvetica;
widget.RecalculateContent();
}
Part of the stack trace:
System.OutOfMemoryException: Insufficient memory to continue the execution of the program.
at System.Text.StringBuilder.ExpandByABlock(Int32 minBlockCharCount)
at System.Text.StringBuilder.AppendWithExpansion(Char value)
at System.Text.StringBuilder.Append(Char value)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Utilities.CrossReferenceCollectionReader.GetAllText(Reader reader, Int64 minOffset, Int64 maxOffset)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Utilities.CrossReferenceCollectionReader.FindAllObjectOffsets(Reader reader, Dictionary`2 tokenToOffsets, Int64 minOffset, Int64 maxOffset)Solution - use the ExpandableMemoryStream for the import instead.
PDF content:

Exported text content:

The current implementation of IDisposable implements a simple Dispose method which releases the inner stream resource. However, if the PdfStreamWriter instance is not disposed explicitly by calling Dispose() or by surrounding it in "using" clause, then the inner Stream resource is not Disposed as well. The same applies for PdfFileSource class. We should implement the IDisposable pattern in a way that the GC disposes the inner stream if needed when collecting the PdfStreamWriter/PdfFileSource class instances.
The hierarchical document structure is a means to describe the PDF document structure, which is currently not supported. See 10.6.1 Structure Hierarchy on 856 page of the PDF specification for details. This document structure is an alternative to the standard PDF structure and most non-Adobe software does not support it. The document might have been created with Adobe software like Adobe LiveCycle Designer. Very often the document contains some fallback text in the standard PDF structure like: "Please wait... If this message is not eventually replaced by the proper contents of the document, your PDF viewer may not be able to display this type of document." "The document you are trying to load requires Adobe Reader 8 or higher. You may not have the Adobe Reader installed or your viewing environment may not be properly configured to use Adobe Reader. For information on how to install Adobe Reader and configure your viewing environment please see http://www.adobe.com/go/pdf_forms_configure." "For the best experience, open this PDF portfolio in Acrobat X, Reader X, or later."
Registering the font used to be enough for resolving the font's characters in .NET Standard
byte[] fontData = File.ReadAllBytes(".\\files\\cour.ttf");
FontFamily courierNewFont = new FontFamily("Courier New");
FontsRepository.RegisterFont(courierNewFont, FontStyles.Normal, FontWeights.Normal, fontData);However, as of version 2024.2.426 registering the font doesn't produce the correct result anymore and the text got missing in the PDF fields. When the document is opened in Adobe, the following message appears:
The FontsProvider works in both versions (before and after 2024.2.426). It is also required to iterate all widgets and apply the font explicitly to the widget.TextProperties.Font property.
The TextProperties.FontSize property specifies the font size for text fragments. The property is of type double. The measurement unit used for font size in RadPdfProcessing is Device Independent Pixels (DIPs). You can convert it to points or other units using the Unit class.
However, when using the TextProperties with widgets the font conversion is not correct. Let's consider the case that we build a PDF document with a TextBoxField occupying a specific rectangle. According to the set text value, we should calculate the appropriate font size so the whole content can fit in the widget's rectangle.
/// <summary>
/// Creates a TextBoxField with calculated font size for the given rectangle
/// </summary>
private static TextBoxField CreateTextBoxWithCalculatedFont(string name, string text, Rect rect, double fontSize, FontBase font)
{
TextBoxField field = new TextBoxField(name);
field.TextProperties.FontSize = Unit.DipToPoint(fontSize);
field.TextProperties.Font = font;
field.Value = text;
var widget = field.Widgets.AddWidget();
widget.Rect = rect;
widget.Border.Width = 0;
widget.TextProperties.FontSize = Unit.DipToPoint(fontSize);
widget.TextProperties.Font = font;
return field;
}
/// <summary>
/// Calculates the optimal font size for text to fit within a specific rectangle
/// </summary>
public static double CalculateFontSizeForRectangle(string text, Rect rect, FontBase font)
{
double fontSize = 0;
Size measuredSize = new Size(0, 0);
Size availableSize = rect.Size;
while (measuredSize.Width<availableSize.Width && measuredSize.Height< availableSize.Height)
{
fontSize++;
Block block = new Block();
block.TextProperties.FontSize = fontSize;
block.TextProperties.Font = font;
block.InsertText(text);
measuredSize = block.Measure();
}
return fontSize-1;
} // Example: Wide textbox with calculated font size
string wideText = "This is a wide textbox that demonstrates horizontal fitting of text content.";
Rect wideRect = new Rect(200, 500, 400, 30);
double wideFontSize = CalculateFontSizeForRectangle(wideText, wideRect, font);
TextBoxField wideTextBoxField = CreateTextBoxWithCalculatedFont("WideTextBox", wideText, wideRect, wideFontSize, font);
document.AcroForm.FormFields.Add(wideTextBoxField);
var wideWidget = wideTextBoxField.Widgets.First();
page.Annotations.Add(wideWidget);
wideWidget.RecalculateContent();
PDF/A-1a is with conformance level A (for "accessibility"), and must adhere to all of the requirements of the PDF Reference as modified by the ISO 19005 specification. It requires structural and semantic properties to be preserved. Level 1a uses “Tagged PDF” and Unicode character maps to preserve the document's logical structure and content text stream in natural reading order. The following features are used: - Language specification - Hierarchical document structure - Tagged text spans and descriptive text for images and symbols - Character mappings to Unicode The purpose is to improve accessibility and make the content accessible for screen readers.
For complienace level PDF/A-2a please follow: PdfProcessing: Add support for PDF/A-2a compliance level.
The currently supported compliance levels can be found in the How to Comply with PDF/A Standard article.
Currently the DocumentInfo property is for export purposes only and meta information about documents is stripped when importing.
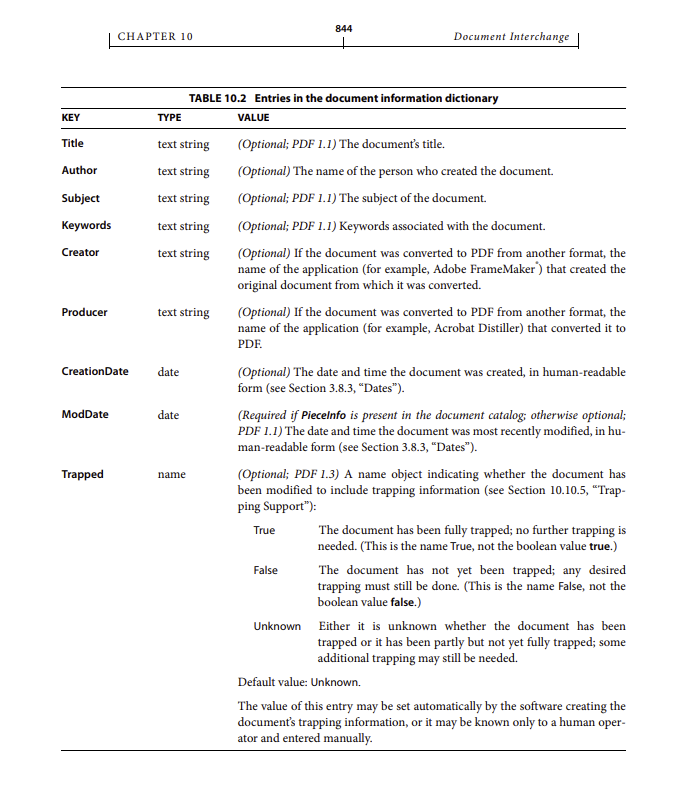
According to the PDF specification (ISO 32000), the document info dictionary (often called "metadata" or "Info" dictionary) can include the following standard fields:
• Title: The document’s title.
• Author: The name of the person who created the document.
• Subject: The subject of the document.
• Keywords: Keywords associated with the document.
• Creator: The application that created the original document.
• Producer: The application that converted the document to PDF.
• CreationDate: The date and time the document was created.
• ModDate: The date and time the document was last modified.
• Trapped: Indicates whether the document has been trapped (a printing term).
These fields are stored in the PDF’s Info dictionary and are used by PDF viewers for display, search, and indexing.
Purpose: Long-term archiving of electronic documents with full semantic structure.
- "A" for Archiving
Level "1a" ensures:
Tagged PDF (with proper logical structure and reading order)
Unicode text for proper text extraction and searchability
Embedded fonts (for consistent rendering)
Restrictions:
No audio/video
No encryption
No JavaScript
No external content (everything must be self-contained)
Based on: PDF 1.4 (Acrobat 5)
Error message:
System.InvalidCastException: 'Unable to cast object of type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfArray' to type 'Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Functions.FunctionObject'.'The PDF/A-1 standard uses the PDF Reference 1.4 and specifies two levels of compliance:
- PDF/A-1b - Its goal is to ensure reliable reproduction of the visual appearance of the document.
- PDF/A-1a - Its objective is to ensure that documents content can be searched and re-purposed. This compliance level has some additional requirements:
- Document structure must be included.
- Tagged PDF.
- Unicode character maps
- Language specification.
Since the PdfProcessing and its PdfFormatProvider is compliant with the PDF Reference 1.7. , the produced documents are created with this version as well:

Implement Viewer related properties in PdfProcessing in order to enable the users to set PrintScaling, Duplex, and other properties which are written in the Pdf Format specification as Interactive Features. ViewerPreferences are written a document's catalog. Check p.577 from pdf reference format specification, version 1.7
It would be great if the SkiaImageExportSettings offer a DocumentUnhandledException event allowing the developer to handle specific errors when exporting to image formats.
This would be an essential improvement in the existing Exception handling mechanism and would enable exporting PDF documents to images even though some parts of the image may not be completely supported: https://docs.telerik.com/devtools/document-processing/libraries/radpdfprocessing/features/handling-document-exceptions