Some documents loaded through WordsProcessing and then exported to a RadFixedDocument by utilizing the ExportToFixedDocument() method, fails on export through ImageFormatProvider with System.AggregateException.
As a workaround, you can export the RadFixedDocument to a PDF and then import it again before exporting it to an image.
var pdfFixedProvider = new Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.PdfFormatProvider();
bytes = pdfFixedProvider.Export(fixedDocument);
fixedDocument = pdfFixedProvider.Import(bytes);
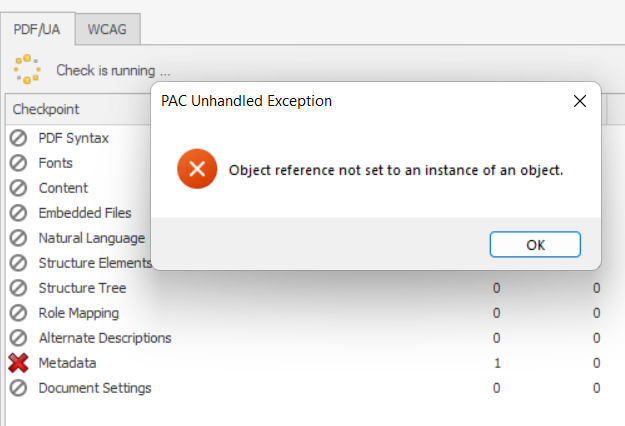
when parsing a specific document.
When loading a PDF generated with PdfProcessing in PDF Accessibility Checker 2021 (PAC) an exception is thrown: "Object reference not set to an instance of an object".
It is reproducible with all PdfComplianceLevel export options.
According to the PDF specification: "It is recommended that there be an end-of-line marker after the data and before endstream;"
The full stack trace:
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.Parser.Reader.Read(Int32 count)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfStreamBase.CalculateStreamLengthAndReadData()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfStream.ReadRawPdfDataOverride()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfStreamBase.ReadRawPdfData()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Filters.FiltersManager.Decode(PostScriptReader reader, IPdfImportContext context, PdfDictionary dictionary, PdfStreamBase stream, PdfArray filters)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfStreamBase.DecodePdfData()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfStreamBase.ReadDecodedPdfData()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Functions.FunctionObject.InterpretData(PostScriptReader reader, IPdfImportContext context, PdfStreamBase stream)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Common.PdfStreamObjectBase.LoadOverride(PostScriptReader reader, IPdfImportContext context, IPdfPrimitive primitive)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Common.PdfObject.Load(PostScriptReader reader, IPdfImportContext context, IPdfPrimitive primitive)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Converters.Converter.ConvertFromStream(Type type, PostScriptReader reader, IPdfImportContext context, PdfStream stream)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Converters.Converter.Convert(Type type, PostScriptReader reader, IPdfImportContext context, IPdfPrimitive value)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Converters.Converter.ConvertFromIndirectReference(Type type, PostScriptReader reader, IPdfImportContext context, IndirectReference reference)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Converters.Converter.Convert(Type type, PostScriptReader reader, IPdfImportContext context, IPdfPrimitive value)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfCollectionBase`1.ConvertElementToType[T](PostScriptReader reader, IPdfImportContext context, IPdfPrimitive element)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Types.PdfCollectionBase`1.TryGetElement[T](PostScriptReader reader, IPdfImportContext context, TIndex index, T& element)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Functions.StitchingFunctionObject.ToFunction(PostScriptReader reader, IPdfImportContext context)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Patterns.GradientShadingObject`1.InitializeGradientStops(PostScriptReader reader, IPdfContentImportContext context, Gradient gradient, Matrix matrix, Double distance)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Patterns.GradientShadingObject`1.ToColorOverride(PostScriptReader reader, IPdfContentImportContext context, Matrix matrix)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.Patterns.ShadingObject.ToColor(PostScriptReader reader, IPdfContentImportContext context, Matrix matrix)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Operators.Color.SetShadingPatternColor.Execute(IContentStreamInterpreter interpreter, IPdfContentImportContext context)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.ContentStreamInterpreter.ExecuteOperatorOverride(ContentStreamOperator oper)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.InterpreterBase`1.<>c__DisplayClass8_0.<Execute>b__0()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.ExceptionHandling.ExecutionHandler.TryHandleExecution[E](Action operation, Action`1 onException)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.InterpreterBase`1.Execute()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.DocumentStructure.ContentStream.ParseContentData(Byte[] data, IRadFixedDocumentImportContext context, IResourceHolder resourceHolder, IContentRootElement contentRoot, ContentStreamKeywordCollection keywordCollection)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.DocumentStructure.ContentStream.ParseContentData(Byte[] data, IRadFixedDocumentImportContext context, IResourceHolder resourceHolder, IContentRootElement contentRoot)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.DocumentStructure.ContentStream.CopyPropertiesTo(IRadFixedDocumentImportContext context, IResourceHolder resourceHolder, IContentRootElement contentRoot)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.DocumentStructure.Page.CopyPageContentTo(IRadFixedDocumentImportContext context, RadFixedPage fixedPage)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.DocumentStructure.DocumentCatalog.<>c__DisplayClass59_1.<CopyAllPageProperties>b__1()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.ExceptionHandling.ExecutionHandler.TryHandleExecution[E](Action operation)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.DocumentStructure.DocumentCatalog.CopyAllPageProperties(PostScriptReader reader, IRadFixedDocumentImportContext context, List`1 contextPages, IList`1 pages)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.DocumentStructure.DocumentCatalog.CopyPagePropertiesTo(PostScriptReader reader, IRadFixedDocumentImportContext context)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.DocumentStructure.DocumentCatalog.CopyPropertiesTo(PostScriptReader reader, IRadFixedDocumentImportContext context)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.RadFixedDocumentImportContext.BeginImportOverride()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.BaseImportContext.BeginImport(Stream pdfFileStream)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.PdfImporter.Import(Stream input, IPdfImportContext context)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.PdfFormatProvider.<>c__DisplayClass18_0.<ImportOverride>b__0()
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.ExceptionHandling.ExecutionHandler.TryHandleExecution[E](Action operation)
at Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.PdfFormatProvider.ImportOverride(Stream input)
at Telerik.Windows.Documents.Common.FormatProviders.FormatProviderBase`1.Import(Stream input)
at PdfOverflow.Program.Main(String[] args) in C:\Users\dyordano\OneDrive - Progress Software Corporation\MyProjects\1633033_pdfoverflow\PdfOverflow\PdfOverflow\Program.cs:line 15
Introduce API for setting Image opacity.
The attached Workaround demonstrates how to change the opacity of the image before inserting it into the document.