When exporting a RadFixedDocument, which contains a signature added with PdfProcessing a NotSupportedException is thrown: 'Stream does not support reading.'
Resolution: When exporting a digitally signed document a stream that allows both reading and writing should be passed to the PdfFormatProvider.
Example:
Stream outputStream = new FileStream("path", FileMode.OpenOrCreate, FileAccess.ReadWrite)
public TestRadForm()
{
InitializeComponent();
this.radPdfViewer1.LoadDocument(@"..\..\..\SampleDocument.pdf");
}
private void radButton1_Click(object sender, EventArgs e)
{
this.radPdfViewer1.Document.AcroForm.FlattenFormFields();
this.radPdfViewer1.SaveDocument(@"..\..\saved.pdf");
}Hi,
Is there a way to get version and producer metadata from imported PDF files?
Here is how it looks in AdobeReader

Thanks in advance,
With the R1 2021 version of our controls RadPdfViewer is using the RadPdfProcessing library model. In this scenario, the PDF document contains images with sizes 87380, 87654. Internally the control is using RenderTargetBitmap to draw the image. So when we pass these values as Width and Height to the constructor of this object an exception occurs. This is a limitation of the RenderTargetBitmap class. It can be reproduced outside of the RadPdfViewer.
RenderTargetBitmap bmp = new RenderTargetBitmap(87380, 87654,96,96,PixelFormats.Pbgra32);As a workaround, we can use the old rendering engine of the control by setting the RadPdfViewer.UsePdfProcessingModel property to false.
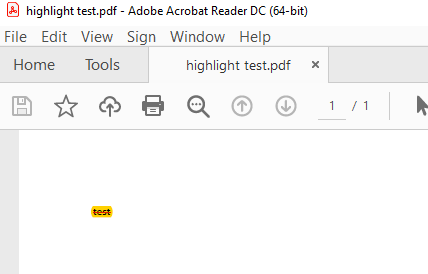
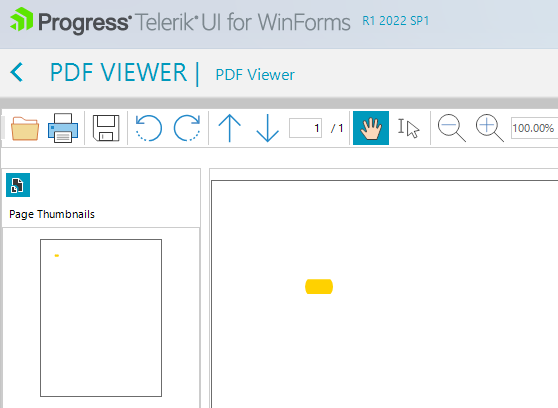
The highlight annotation appears above the text and covers it, instead of appearing under it.
Expected:
Actual:

When there is no ToUnicode CMap, the text from the Simple Font instance should be extracted by mapping the glyph name to its corresponding charcode according to Adobe Glyph List. Additionally, the Differences array should be included in these calculations when there is custom encoding. The current implementation of RadPdfViewer makes ToString to the original char id byte value which leads to wrong characters.