StackOverflowException is thrown during PDF export of a document with a Header/Footer containing a page break.
Workaround: Remove page break from all header/footer paragraphs, or from a specific paragraph.
Header defaultHeader = section.Headers.Default;
if (defaultHeader != null)
{
foreach (var item in defaultHeader.Blocks)
{
if (item is Paragraph paragraph)
{
paragraph.PageBreakBefore = false;
}
}
}
When imported in the WordsProcessing model, the current HTML doesn't respect the defined column width and all columns have identical width:
<colgroup>
<col span="1" style="width: 33.3302%;">
<col span="1" style="width: 17.5658%;">
<col span="1" style="width: 49.104%;">
</colgroup>Observed result:

Expected result:

Workaround: use the width property as follows:
<colgroup>
<col span="1" width="33.3302%">
<col span="1" width="17.5658%">
<col span="1" width="49.104%">
</colgroup>
Multiple CSS classes on an element are not correctly resolved when converted to inline styles.
Before:
.TelerikNormal {font-family: Calibri;font-size: 14.6666666666667px;margin-top: 0px;margin-bottom: 0px;line-height: 100%;color: #000000;}.TelerikHeading3 {font-family: Calibri Light;font-size: 22.6666666666667px;}<p class="TelerikNormal TelerikHeading3"><span>Test</span></p>Due to order priority, the TelerikHeading3 values override the TelerikNormal values. The font-size becomes 22.6666666666667px.
Convert:
provider.ExportSettings.StylesExportMode = StylesExportMode.Inline;
<p style="font-family: Calibri;font-size: 14.6666666666667px;margin-top: 0px;margin-bottom: 0px;line-height: 100%;color: #000000;"><span>Test</span></p>
In case table cell doesn't have directly applied background, it should inherit the background of its parent table.
This is the code for import/export which result is illustrated below:
string inputFilePath = "test1.doc";
Telerik.Windows.Documents.Flow.Model.RadFlowDocument document;
Telerik.Windows.Documents.Flow.FormatProviders.Doc.DocFormatProvider doc_provider = new Telerik.Windows.Documents.Flow.FormatProviders.Doc.DocFormatProvider();
using (Stream input = File.OpenRead(inputFilePath))
{
document = doc_provider.Import(input, TimeSpan.FromSeconds(10));
}
Telerik.Windows.Documents.Flow.FormatProviders.Docx.DocxFormatProvider docx_provider = new Telerik.Windows.Documents.Flow.FormatProviders.Docx.DocxFormatProvider();
string outputFilePath = "Exported.docx";
using (Stream output = File.OpenWrite(outputFilePath))
{
docx_provider.Export(document, output, TimeSpan.FromSeconds(10));
}
Process.Start(new ProcessStartInfo() { FileName = outputFilePath, UseShellExecute = true });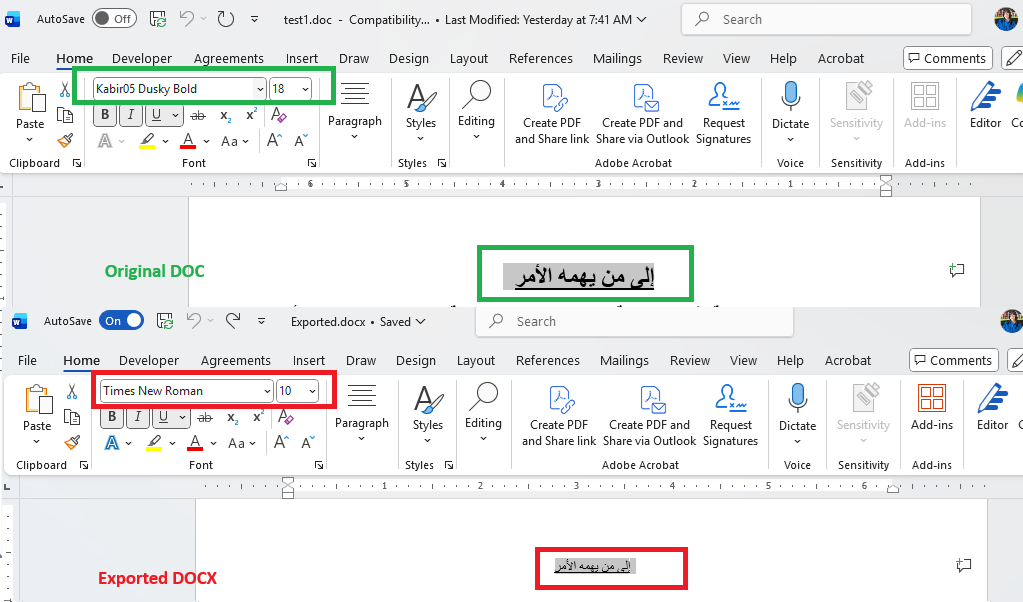
Provide a way to export filters.
An error occurs while importing an XLSX document with charts. Here is the stack trace:
at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Contexts.XlsxWorkbookImportContext.PairSeriesGroupsWithAxes() at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.Chart.PlotAreaElement.CopyPropertiesTo(IOpenXmlImportContext context, DocumentChart chart) at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.Chart.ChartElement.CopyPropertiesTo(IOpenXmlImportContext context, DocumentChart chart) at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.Chart.ChartSpaceElement.OnAfterRead(IOpenXmlImportContext context) at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Elements.OpenXmlElementBase.Read(IOpenXmlReader reader, IOpenXmlImportContext context) at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Parts.ChartPart.Import(IOpenXmlReader reader, IOpenXmlImportContext context) at Telerik.Windows.Documents.FormatProviders.OpenXml.Model.Parts.OpenXmlPartBase.Import(Stream stream, IOpenXmlImportContext context) at Telerik.Windows.Documents.FormatProviders.OpenXml.OpenXmlImporter`1.ImportPartFromArchive(ZipArchiveEntry zipEntry, PartBase part, IOpenXmlImportContext context) at Telerik.Windows.Documents.FormatProviders.OpenXml.OpenXmlImporter`1.Import(Stream input, IOpenXmlImportContext context) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.XlsxFormatProvider.ImportOverride(Stream input, CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.WorkbookFormatProviderBase.Import(Stream input, Nullable`1 timeout)
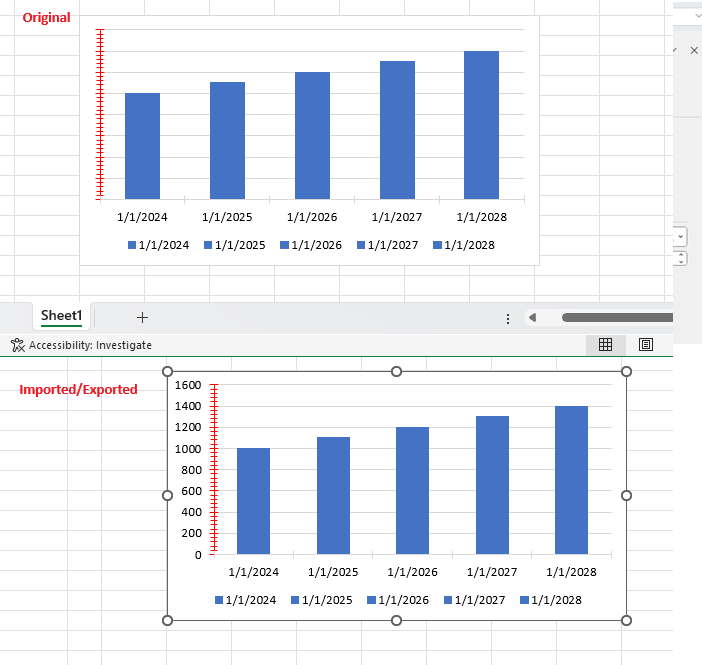
Workaround: this is the missing part after the export:

at Telerik.Windows.Documents.Spreadsheet.Utilities.SpreadsheetHelper.UpdateFloatingImageSize(FloatingShapeBase shape) at Telerik.Windows.Documents.Spreadsheet.Utilities.SpreadsheetHelper.CalculateRotatableShapeBoundingRect(Point position, FloatingTransformableShape shape) at Telerik.Windows.Documents.Spreadsheet.Layout.RadWorksheetLayout.CalculateShapeBoundingRect(FloatingShapeBase shape) at Telerik.Windows.Documents.Spreadsheet.Layout.RadWorksheetLayout.UpdateShapesSizeAndPosition() at Telerik.Windows.Documents.Spreadsheet.Layout.RadWorksheetLayout.Measure(CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.Layout.RadWorksheetLayout.Measure(CellIndex frozenCellIndex, CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.Model.Workbook.UpdateWorksheetLayout(RadWorksheetLayout worksheetLayout, Worksheet worksheet, Boolean isForPrinting, CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.Model.Workbook.GetWorksheetLayout(Worksheet worksheet, Boolean isForPrinting, CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.Model.Workbook.GetWorksheetLayout(Worksheet worksheet, Boolean isForPrinting) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Contexts.XlsxWorksheetImportContext.ImportShapesSizes() at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Contexts.XlsxWorksheetImportContext.EndImport(XlsxWorkbookImportContext workbookContext) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.Contexts.XlsxWorkbookImportContext.EndImport() at Telerik.Windows.Documents.FormatProviders.OpenXml.OpenXmlImporter`1.Import(Stream input, IOpenXmlImportContext context) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.OpenXml.Xlsx.XlsxFormatProvider.ImportOverride(Stream input, CancellationToken cancellationToken) at Telerik.Windows.Documents.Spreadsheet.FormatProviders.WorkbookFormatProviderBase.Import(Stream input, Nullable`1 timeout)
This is causing issues when exporting the document to PDF from WordsProcessing - the pdf library tries to create the font, but cannot find it due to a different casing. When importing HTML document, the font-family property is read with small letters. Later, when converting the string containing the value, it is changed to title case. This issue will be reproducible with each font containing a name with a letter with casing different than the one of the other letters (exc. first capital letter), for example: Microsoft JhengHei