Latest version 2024.2.426:
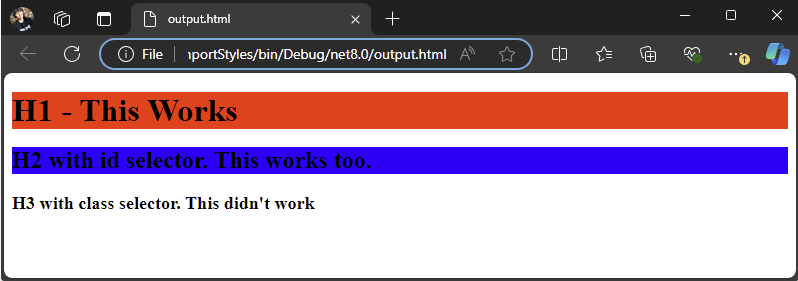
Old version 2022.3.906:
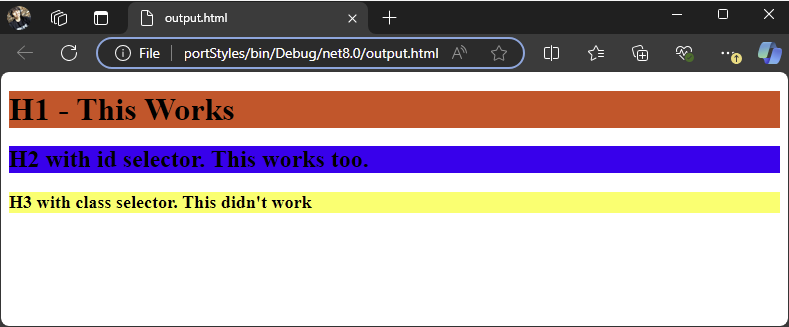
Use the following code:
static void Main(string[] args)
{
Console.WriteLine("Test from 2022.3.906 to 2024.2.426.");
string html = @"<html>
<head>
<style type=""text/css"">
h1 {
background-color: red;
}
#highlight1{
background-color: blue;
}
.highlight2{
background-color: yellow;
}
</style>
</head>
<body>
<h1>H1 - This Works </h1>
<h2 id=""highlight1"">H2 with id selector. This works too.</h2>
<h3 class=""highlight2"">H3 with class selector. This didn't work</h3>
</body>
</html>";
Telerik.Windows.Documents.Flow.FormatProviders.Html.HtmlFormatProvider html_provider = new Telerik.Windows.Documents.Flow.FormatProviders.Html.HtmlFormatProvider();
RadFlowDocument document = html_provider.Import(html);
string html_output = "output.html";
using (Stream output = File.Create(html_output))
{
html_provider.Export(document, output);
}
Process.Start(new ProcessStartInfo() { FileName = html_output, UseShellExecute = true });
}Center alignment is not respected for list numbering.
Expected:

Actual:

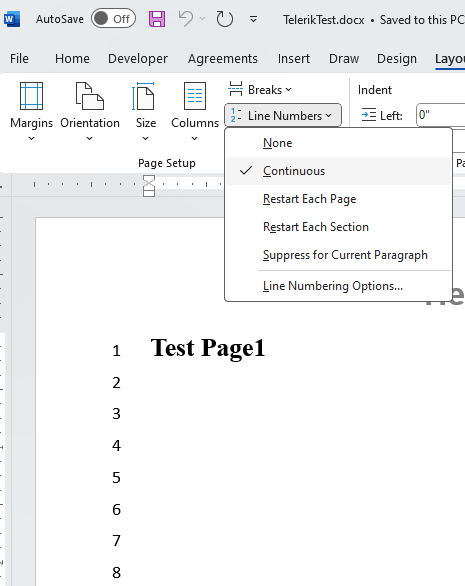
More information about the feature can be found here: https://support.microsoft.com/en-us/office/add-or-remove-line-numbers-b67cd35e-422c-42eb-adc9-256ca9802e22
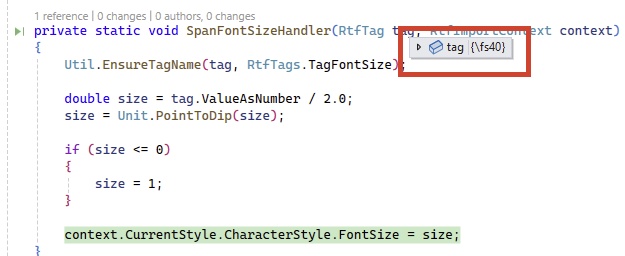
(DIPs) is a unit type used in RadWordsProcessing when setting the FontSize of a Run. If you load a document with font size in WordPad set to 20 points and load it to RadFlowDocument, its value is converted by using the following method. If the RTF content stored from WordPad is saved to HTML format with WordPad, the font size is preserved with the same unit: style='font-size:20.0pt;'. We should add the option to control the font size unit when exporting to HTML format.
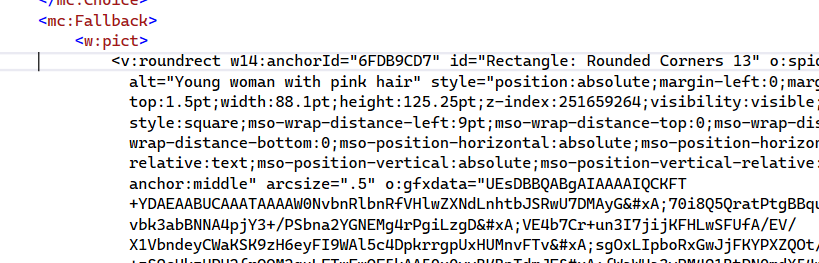
<w:r w:rsidRPr="00CB6D35">
<w:rPr>
<w:rFonts w:ascii="Calibri Light" w:hAnsi="Calibri Light"/>
<w:b/>
<w:u w:val="double"/>
</w:rPr>
<w:t>DETTAGLIO SINISTRO</w:t>
</w:r>When you have indented and justified text, it is wrongly exported to PDF:
<w:pPr>
<w:spacing w:after="0" w:line="360" w:lineRule="auto"/>
<w:ind w:left="567" w:right="567" w:firstLine="708"/>
<w:jc w:val="both"/>
<w:rPr>
<w:rFonts w:ascii="Calibri Light" w:hAnsi="Calibri Light"/>
</w:rPr>
</w:pPr>
Getting an exception message when trying to view a document as a PDF using the PdfFormatProvider which started happening only after upgrading Telerik to the latest version, 7.1.0 in Telerik UI for Blazor.
Exception Message:
width should be greater or equal than 0. (Parameter 'width')
I have copied the stack trace and source of the exception below:
Source: Telerik.Documents.Fixed
Stack Trace: at Telerik.Windows.Documents.Fixed.Model.Editing.Layout.ContentElementLayoutElementBase`1.DrawHighlights(DrawLayoutElementContext context)
at Telerik.Windows.Documents.Fixed.Model.Editing.Layout.ContentElementLayoutElementBase`1.Draw(DrawLayoutElementContext context)
at Telerik.Windows.Documents.Fixed.Model.Editing.Block.Draw(IEnumerable`1 lineElements, DrawLayoutElementContext context)
at Telerik.Windows.Documents.Fixed.Model.Editing.Block.DrawInternal(FixedContentEditor editor, Rect boundingRect)
at Telerik.Windows.Documents.Fixed.Model.Editing.Block.Telerik.Windows.Documents.Fixed.Model.Editing.Flow.IDrawArrangedElement.DrawArrangedElement(FixedContentEditor editor, Rect boundingRect)
at Telerik.Windows.Documents.Fixed.Model.Editing.Flow.SectionInfo.DrawArrangedElement(IBlockElement blockElement, Double horizontalOffset, Double verticalOffset)
at Telerik.Windows.Documents.Fixed.Model.Editing.Utils.SectionInfoExtensions.DrawArrangedElements(SectionInfo section, IList`1 elements)
at Telerik.Windows.Documents.Fixed.Model.Editing.RadFixedDocumentEditor.Draw()
at Telerik.Windows.Documents.Fixed.Model.Editing.RadFixedDocumentEditor.StartNewPage(SectionProperties sectionProperties)
at Telerik.Windows.Documents.Fixed.Model.Editing.RadFixedDocumentEditor.StartNewPage()
at Telerik.Windows.Documents.Fixed.Model.Editing.RadFixedDocumentEditor.AddBlock(IBlockElement blockElement, CancellationToken cancellationToken)
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.Export.PdfExporter.ExportSection(Section section, RadFixedDocumentEditor editor)
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.Export.PdfExporter.ExportDocument(RadFlowDocument document, RadFixedDocumentEditor editor)
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.Export.PdfExporter.ExportInternal()
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.Export.PdfExporter.Export()
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.PdfFormatProvider.ExportToFixedDocument(RadFlowDocument document, CancellationToken cancellationToken)
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.PdfFormatProvider.ExportOverride(RadFlowDocument document, Stream output, CancellationToken cancellationToken)
at Telerik.Windows.Documents.Flow.FormatProviders.Pdf.PdfFormatProvider.ExportOverride(RadFlowDocument document, Stream output)
at Telerik.Windows.Documents.Common.FormatProviders.FormatProviderBase`1.Export(T document, Stream output)
at Telerik.Windows.Documents.Common.FormatProviders.BinaryFormatProviderBase`1.Export(T document)
When converting HTML to DOCX, margins set on an HTML element are ignored. These styles are exported correctly when the HTML passed to the converter is formatted with indents. The following XUnit test demonstrates this behavior with a simplified example.
using Telerik.Windows.Documents.Flow.FormatProviders.Docx;
using Telerik.Windows.Documents.Flow.FormatProviders.Html;
namespace MSPI.Tests.Unit;
public class WordExportTest
{
[Fact]
public async Task TextExport()
{
const string formattedDocumentSavePath = @"C:\Testing\export-test-formatted.docx";
const string formattedContent = """"
<p>Test paragraph</p>
<ol style="margin-left: 100px;">
<li>Item 1</li>
<li>Item 2</li>
</ol>
"""";
const string minifiedDocumentSavePath = @"C:\Testing\export-test-minified.docx";
const string minifiedContent = """"<p>Test paragraph</p><ol style="margin-left: 100px;"><li>Item 1</li><li>Item 2</li></ol>"""";
var htmlFormatProvider = new HtmlFormatProvider();
var docxFormatProvider = new DocxFormatProvider();
await using var minifiedDocumentMemoryStream = new MemoryStream();
var minifiedRadFlowDocument = htmlFormatProvider.Import(minifiedContent, TimeSpan.FromSeconds(30));
docxFormatProvider.Export(minifiedRadFlowDocument, minifiedDocumentMemoryStream, TimeSpan.FromSeconds(30));
var minifiedBytes = minifiedDocumentMemoryStream.ToArray();
await File.WriteAllBytesAsync(minifiedDocumentSavePath, minifiedBytes);
await using var formattedDocumentMemoryStream = new MemoryStream();
var formattedRadFlowDocument = htmlFormatProvider.Import(formattedContent, TimeSpan.FromSeconds(30));
docxFormatProvider.Export(formattedRadFlowDocument, formattedDocumentMemoryStream, TimeSpan.FromSeconds(30));
var formattedBytes = formattedDocumentMemoryStream.ToArray();
await File.WriteAllBytesAsync(formattedDocumentSavePath, formattedBytes);
}
}The minified HTML produces the following document:
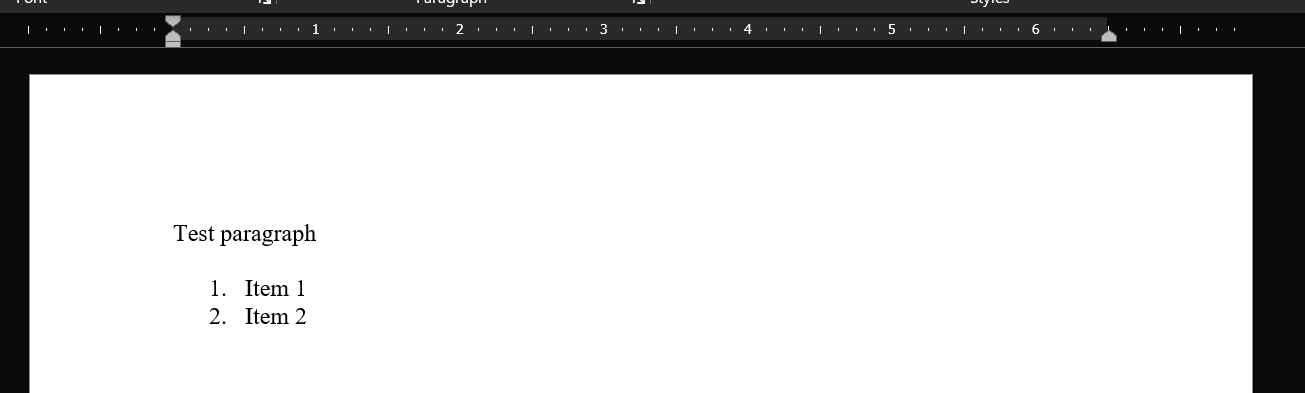
The formatted HTML produces the following document:
