.../AP<</N<</Off null/Yes 439 0 R>>...
Parameter name: form'
When a row has two cells and the content of the first one is large, the width of the second cell results in too small value while measuring and its content remains invisible.
Workaround: Set PreferredWidth to the second cell.
When a Table consisting of one TableRow that contains a TableCell with a Rowspan > 1 set, additional lines are added to the table.
Table table = new Table();
TableRow row = table.Rows.AddTableRow();
row.Cells.AddTableCell();
TableCell secondCell = row.Cells.AddTableCell();
secondCell.RowSpan = 2;
table.Measure();
table.Rows.AddTableRow();
According to the PDF Specification: The first entry in the table (object number 0) is always free and has a generation number of 65,535;
An invalid xref table:
xref 1 3 0000000010 00000 n 0000000124 00000 n 0000011290 00000 n
xref 0 4 0000000000 65535 f 0000000010 00000 n 0000000124 00000 n 0000011290 00000 n
When exporting PDF documents containing images different than Jpeg and Jpeg2000 the PdfProcessing is using by default the ImageSharp library in order to convert these images to Jpeg.
It seems there is an issue in the older version of the ImageSharp library: Saving a PNG as Jpeg only processes a part of the image on .NET 6.
Workaround: This issue seems to be fixed in the current version (2.0.0) of the ImageSharp library.
PdfFormatProvider: When Arial Narrow Bold fond is set in the document the font-weight is lost when converting to PDF.
Workaround:
var fontData = File.ReadAllBytes(@"C:\Downloads\arial-narrow\arialnb.ttf");
FontsRepository.RegisterFont(new System.Windows.Media.FontFamily("Arial Narrow"), FontStyles.Normal, FontWeights.Bold, fontData);
This would allow to encrypt documents only with Owner Password and not showing password dialog when disabling some PDF features permissions. The customer should be able to disable printing, text and graphic selection and extraction, page rotations and others. The full specification of all permission bits may be seen in Table 3.20 on page 124 in PdfReference 1.7. On page 120 in PdfReference 1.7 are described the User and Owner passwords.
Currently, the text extraction is following the behavior (text distance) as exported with Adobe.
Provide a setting in TextFormatProvider in order to keep the original distance as in the PDF document.
When importing a not embedded TrueType Font defined as Type 1 subtype Font an InvalidCastException is thrown.
In PDF document:
<< /BaseFont /Arial /Encoding 21 0 R /Name /F13 /Subtype /Type1 /Type /Font >>In Adobe Reader:
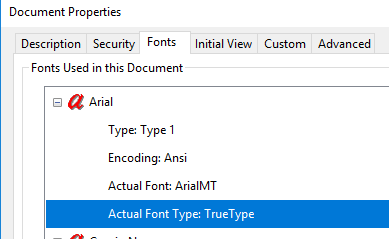
When the Font`s Widths array contains entries defined as Indirect references an exception is thrown: System.ArgumentException: 'The IndirectReference type cannot be converted to a real numeric value.'
According to the Pdf Specification: The glyph widths are measured in units in which 1000 units corresponds to 1 unit in text space.
URI Action with invalid mailto URL scheme - mailto:***@***.**(E-mail) can be imported but trying to merge or clone the document throws UriFormatException: 'Invalid URI: The hostname could not be parsed.'
Workaround: Remove the annotations that contain invalid Uri:
PdfFormatProvider provider = new PdfFormatProvider();
this.pdfDocument = provider.Import(memory);
foreach (var page in this.pdfDocument.Pages.ToList())
{
List<Link> links = page.Annotations.Where(a => a.Type == AnnotationType.Link).Select(a => a as Link).ToList();
foreach (var link in links)
{
Uri uri;
UriAction uriAction = link.Action as UriAction;
try
{
uri = uriAction.Uri;
}
catch (UriFormatException)
{
page.Annotations.Remove(link);
}
}
}
Currently, NotSupportedException is thrown when trying to import a document that uses Type 3 fonts.
Update: With Release R1 2021 the import of Type 3 fonts is already developed but the export is still not supported.