This exception was originally thrown at this call stack:
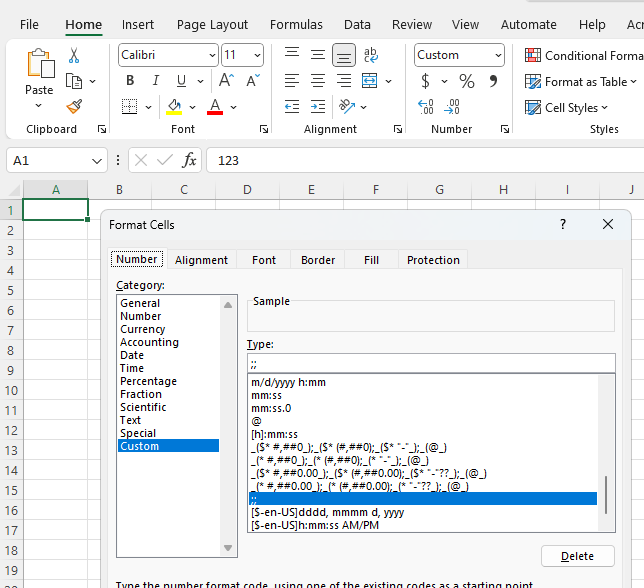
Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Model.Elements.DocumentStructure.DocumentCatalog.CopyEmbeddedFilesTo(Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.Parser.PostScriptReader, Telerik.Windows.Documents.Fixed.FormatProviders.Pdf.Import.IRadFixedDocumentImportContext) in DocumentCatalog.csImport the document with RadSpreadProcessing and export it PDF format. You will notice that the cell value is displayed in the exported PDF document while in the Excel file it is hidden due to the custom format:
Currently, a NullReferenceException is thrown because of the incorrect structure.
As a workaround, the exception can be handled using the Handling Exceptions mechanism.
Update:
When importing documents with invalid structure of path construction operators an InvalidGraphicOperandsCountException is thrown which could be handled using the Handling Exceptions mechanism.
PdfFormatProvider provider = new PdfFormatProvider();
provider.ImportSettings.DocumentUnhandledException += this.ImportSettings_DocumentUnhandledException;
private void ImportSettings_DocumentUnhandledException(object sender, DocumentUnhandledExceptionEventArgs e)
{
if (e.Exception is InvalidGraphicOperandsCountException)
{
e.Handled = true;
}
}
I'm currently working with the large PDFs. I'm able to process PDFs up to 2.1 GB easily without any error using Telerik Document Processing. However, if I take a larger PDF (e.g. 2.8 GB), PdfFormatProvider.Import throws an IOException with the next message: "The parameter is incorrect. : {path}".
I'm using FileStream to provide a sample for the Import method.
I've checked it with the different samples, all have the same behavior. So, I guess, it will work for any PDF larger than 2.1 GB.
16 0 obj <</AP<</N<</Off null/On 188 0 R>>/D<</Off 189 0 R/On 190 0 R>>>>/AS/Off/F 4/FT/Btn/H/T/P 19 0 R/Rect[ 40.3 690.45 56.15 706.7999]/Subtype/Widget/T(Einraeumung:Grabnutzungsrechts)/Type/Annot>> endobj
SkiaImageFormatProvider: Rectangle behind text overlaps the text of previous line.
RESOLVED: The issue is dismissed. The actual reason for the results is missing FontsProvider implementation. In order for accurate calculations and measurements the fonts used in the document need to be resolved correctly.
Handle import of documents with wrong type of action key.

Once this is completed use the Exceptions Handling mechanism to handle this scenario. For instance:
private void ImportSettings_DocumentUnhandledException(object sender, DocumentUnhandledExceptionEventArgs e)
{
if (e.Exception is InvalidActionException)
{
As a result of the below missing operator, some of the glyphs can't be extracted from the CFFFontTable and the characters are not displayed in the PdfViewer:
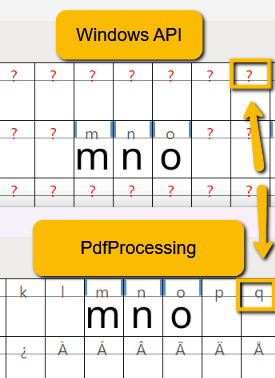
The end user result is missing letter from the PDF content.
Encoding table headers are preserved when creating subsets.
NullReferenceException is thrown when Find API is used on a newly created document.
Workaround: Export - Import the document before using the Find API
PdfFormatProvider pdfFormatProvider = new PdfFormatProvider();
byte[] exportedDocument = pdfFormatProvider.Export(document);
document = pdfFormatProvider.Import(exportedDocument);